郭健教授招收『人工智能与量化投资』、『深度学习与大模型』交叉方向博士生!
IDEA-香港科技大学(广州)联培博士项目常年招生,希望从事人工智能、AI量化投资研究的同学欢迎联系我!相关招生信息可以访问IDEA-HKUST(GZ)博士招生网站:
https://www.idea.edu.cn/research/idea-co-edu.htmlIDEA诚聘AI量化金融研究员(全职、实习)!
人工智能金融与深度学习研究中心长期招聘:AI金融研究员、AI金融工程师、实习研究员(Intern)、研究助理(RA)。如您相关工作或实习感兴趣,可访问以下网页获取更多信息:
https://idea.zhiye.com/

郭健 博士 国家特聘专家
首席科学家、(署理)院长
粤港澳大湾区数字经济研究院(IDEA)
粤港澳大湾区数字经济研究院(IDEA)
DeepX创始人,并兼任港科大、上海交大、清华兼聘教授/博导
研究方向: 量化投资 人工智能 深度学习
个人简介(Biography)
郭健是IDEA首席科学家、(署理)院长,并兼任香港科技大学(广州)人工智能学域兼职教授(博士生导师)、上海交通大学上海高级金融学院(SAIF)兼聘教授、清华大学深圳国际研究生院(数据与信息研究院)实践教授。郭健2003年从清华大学数学科学系本科毕业后在IT领域创业多年,2006年赴美国密西根大学(University of Michigan)统计系深造并取得机器学习专业的博士学位。郭健自2011年起任美国哈佛大学(Harvard University)计算统计学助理教授(Tenure-track、博士生导师),深耕人工智能的数学和统计学算法研究,特别是在机器学习和深度学习的理论、算法和应用领域取得一系列研究成果,并广泛实践于金融量化投资、搜索推荐引擎、基因疾病预测等领域。2016年郭健回国创业,创建DeepX,研发新型人工智能技术用于金融市场量化投资与风险管理研究。2020年,郭健因其在学术研究和产业创新方面的贡献被授予国家特聘专家荣誉。同年他协助美国国家工程院外籍院士、前微软公司全球执行副总裁沈向洋共同创建了粤港澳大湾区数字经济研究院(International Digital Economy Academy, 简称IDEA),汇聚全球具有“科学家头脑、企业家素质、创业者精神”的科创实干家共同推动人工智能前沿技术与新兴产业发展。
郭健长期深耕人工智能与深度学习理论、算法与应用研究,聚焦新一代AI量化投资技术的前沿探索和系统研发,发表研究论文60+篇,开源技术报告20+篇,技术发明专利10+项,软件著作权10+项,开源项目5+项。在AI基础研究方面,郭健团队研发了增强大语言模型知识推理能力和逻辑链可追溯能力的“思维图谱(Think-on-Graph)”技术,提出了面向大语言模型的下一代知识图谱技术范式与开源自动化知识库构建技术“语境图谱(Context Graph)”。在AI算法研究方面,郭健提出了解决多阶段决策问题中端到端深度学习训练难题的“向导学习(Guided Learning)”技术,并应用于自动驾驶和量化投资的端到端决策中。在AI量化投资研究方面,郭健与沈向洋院士共同提出了新一代AI量化投资技术范式Quant4.0和并研发了全流程自动化AI量化投资研究平台ideaQuant。更进一步,郭健与沈向洋提出Quant5.0,建立跨市场、跨品种、跨周期的端到端金融时间序列预训练底座大模型(Large Investment Model),提升量化投资的模型研发效率和策略迁移能力。与此同时,郭健团队还研发了世界首个基于大语言模型的AI量化投资建模智能体Alpha-GPT,在WorldQuant Brain等全球量化投资策略比赛中取得世界领先名次。
以下两个短片分别介绍了IDEA研究院(左侧视频)和郭健团队的部分研究内容(右侧视频)。
学术观点(Perspectives)










研究项目(Research)
郭健目前聚焦于研发前沿的人工智能技术让金融投资更精准、更迅捷、更安全。研究围绕未来金融投资和量化交易所需的新型人工智能技术、新型大模型研究范式和新型深度学习算法展开。
Quant5.0:面向量化投资的金融时间序列底座大模型
多模态大语言模型的快速发展证明了利用海量样本预训练的深度学习底座模型在经过增量微调或强化学习后训练后在特定任务上展现出前所未有的性能。我们将这一范式移植到量化投资场景中的金融时间序列预测问题中,收集不同交易所(上交所、深交所、港交所、纽交所等)、不同交易品种(股票、期货、可转债等)和不同周期(订单簿、秒线、分钟线、日线等)的金融数据来训练通用的金融时间序列底座深度神经网络模型,并在各类型量化投资任务中进行增量微调或RL后训练以提升针对任务的预测能力。

e2eQuant:面向量化投资的端到端深度学习模型
深度神经网络端到端量化投资建模跨越因子挖掘、机器学习建模、投资组合优化、算法交易等多个步骤,从最原始的数据输入(行情、订单簿等)直接输出下一秒的订单交易指令,可以显著简化建模过程并提升交易性能。由于金融时序数据低信噪比、非平稳等特定,端到端建模存在神经网络收敛难、模型训练不稳定、模型推理延迟大等一系列问题亟待研究解决。我们研发了Guided Learning、鲁棒学习等一系列新技术来提升端到端量化投资模型的投资效果和稳定性。

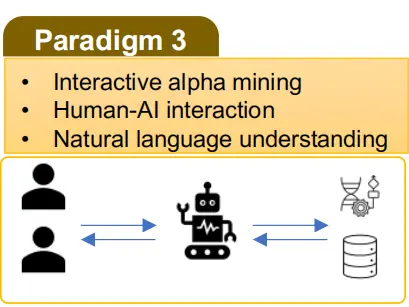
Alpha-GPT:面向量化投研的AI智能体
Alpha-GPT是世界首个开放式人机交互式量化投研智能体系统,并随着大模型领域的快速发展而不断进化。通过Self-improving、rethink、强化学习后训练等技术来激发和提升大模型在量化因子挖掘、量化深度学习建模等能力。我们也从数学理论上给出了self-improving合理性的论证。
Quant4.0:面向量化投研的全流程自动化深度学习建模系统
以多因子选股模型为代表的量化投资建模是一个多阶段决策问题,包括特征工程(因子挖掘)、模型构建(因子组合)、投资组合(仓位优化)、拆单执行(算法交易)等多个步骤,最后输出交易指令。Quant4.0的目的是通过人工智能技术实现量化投资建模全流程自动化,研发更高效的自动特征工程、自动化深度学习调优算法、自动化深度学习部署与推理加速等技术以提升投研效率,将量化投资从“人工建模”进化为“机器建模”。进一步,利用大语言模型提升自动化因子挖掘和自动化深度学习建模的智能水平。
金融风洞:AI金融行为模拟系统
量化投资通常利用历史数据回测模拟来评估策略、模型和因子的效果。然而,历史不代表未来,历史没有发生的极端行情不代表未来不会发生。我们研发“金融风洞”来模拟历史上尚未发生的各种极端行情,对交易策略进行压力测试。金融风洞项目研发生成式深度神经网络和多模态大模型,通过学习全球不同金融交易市场的行情数据和来自财经新闻、企业公告等金融事件,理解金融市场运行规律,并以此来根据用户需求来生成新的金融行情时间序列,对各种极端行情进行高精度模拟,建立比回测更准确更全面的策略评估体系。

语境图谱:面向大模型的新一代知识图谱技术
我们提出语境图谱(Context Graph)技术。在传统三元组型知识图谱的基础上,进一步将时间、空间、来源、文本描述等多维上下文信息与实体及关系一并建模,以构建更为精细和丰富的知识表示结构。它不仅包含“头实体–关系–尾实体”的基本事实三元组,还为每条事实附加了实体上下文(如摘要、别名、图片链接)和关系上下文(如时间戳、地理位置、出处句子等),从而克服了纯三元组图在语义歧义、信息不完整和推理局限等方面的不足,可以更好的帮助大语言模型进行精准可追溯的深度推理。同时,我们正在研发全自动化的语境图谱构建技术。
技术专著(Books)

赵勇、林辉、沈抖、郭健等 (2014) 《大数据革命——理论、模式与技术创新》。 电子工业出版社,2014.08。ISBN 9787121237652。
注:本书是郭健教授在美国哈佛大学任教期间与百度集团执行副总裁沈抖博士、前微软公司技术总监赵勇博士等多位人工智能专家共同创作,是国内最早的系统性介绍大数据技术的书籍之一。
大数据技术是以数据为本质的新一代革命性的信息技术,在数据挖潜过程中,能够带动理念、模式、技术及应用实践的创新。本书系统性地介绍了大数据的概念、发展历程、市场价值、大数据相关技术,以及大数据对中国信息化建设、智慧城市、广告、媒体等领域的核心支撑作用,并对数据科学理论做了初步探索。
已发表的学术论文 (Publications)
注:*代表本人是论文通讯作者或共同通讯作者, †代表本人是论文共同第一作者

Wanyun Zhou, Saizhuo Wang, Xiang Li, Yiyan Qi, Jian Guo, Xiaowen Chu (2025) Unleashing Expert Opinion from Social Media for Stock Prediction. Transactions on Knowledge and Data Engineering. To appear.
该论文针对金融市场lead-lag效应,提出首个端到端深度学习方法DeltaLag,解决传统统计方法依赖线性度量、假设关系稳定的局限。它用稀疏交叉注意力动态识别股对领先滞后关系及滞后值,结合MLP预测滞后股未来收益,统一检测与预测阶段。实验显示其显著优于固定滞后、自领先滞后基线及统计预计算图,还超越多种时序/时空深度学习模型,兼具更好交易表现与更强可解释性。
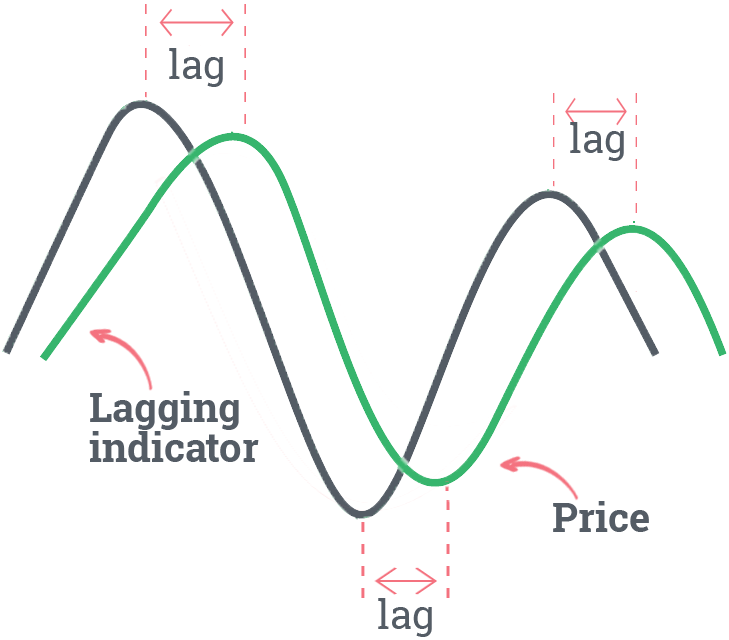
Wanyun Zhou, Saizhuo Wang, Mihai Cucuringu, Zihao Zhang, Xiang Li, Jian Guo, Chao Zhang, Xiaowen Chu (2025) DeltaLag: Learning Dynamic Lead-lag Patterns in Financial Markets. The 6th ACM International Conference on AI in Finance (ICAIF-2025), Singapore.
该论文针对金融市场lead-lag效应,提出首个端到端深度学习方法DeltaLag,解决传统统计方法依赖线性度量、假设关系稳定的局限。它用稀疏交叉注意力动态识别股对领先滞后关系及滞后值,结合MLP预测滞后股未来收益,统一检测与预测阶段。实验显示其显著优于固定滞后、自领先滞后基线及统计预计算图,还超越多种时序/时空深度学习模型,兼具更好交易表现与更强可解释性。

Peixian Ma, Xialie Zhuang, Chengjin Xu, Xuhui Jiang, Ran Chen, Jian Guo* (2025) SQL-R1: Training Natural Language to SQL Reasoning Model By Reinforcement Learning. The Thirty-Ninth Annual Conference on Neural Information Processing Systems (NeurIPS-2025), San Diego, CA, USA.
SQL-R1是一种基于强化学习的自然语言转SQL推理模型,通过设计针对NL2SQL任务的强化学习奖励函数和冷启动策略,在Spider和BIRD基准测试上分别达到88.6%和67.1%的执行准确率。该模型采用GRPO算法进行训练,仅需少量合成数据即可实现高性能,显著提升了复杂场景下的推理能力,并为低信噪比环境中的过拟合和分布偏移问题提供了解决方案。。
Saizhuo Wang, Fengrui Hua, Jiahao Zheng, Hao Kong, Jian Guo* (2024) QuantBench: Benchmarking AI Modeling for Quantitative Investment. Frontiers of Information Technology and Electronic Engineering. To Appear.
本文提出QuantBench,首个面向量化投资的工业级AI基准平台,填补了该领域标准化评估工具的空白。其核心创新包括:1)全流程覆盖:整合因子挖掘、建模、组合优化与订单执行四大环节,支持跨任务评估(表1);2)多层次设计:通过分层架构(图1)统一数据、模型与评估,增强可复现性;3)关键发现:实验揭示深度网络在IC指标上较XGBoost提升57%(表2),但树模型在Sharpe比率上更具优势;自适应图神经网络(如THGNN)以4.93% IC领先(表3);4)行业价值:平台显著缓解数据长尾问题,推动学界与工业界协同创新,为低信噪比环境下的过拟合问题(图5)及分布偏移(图4)提供解决方案。

Jian Guo* and Heung-Yeung Shum (2025) Large Investment Model. Frontiers of Information Technology and Electronic Engineering. Issue 10, 2025.
注:本文被FITEE期刊选为2025年第10期封面文章。
本文提出Large Investment Model (LIM),一种基于跨市场、跨品种、跨周期的金融时间序列预训练的量化投资新范式。LIM通过端到端学习和通用建模构建上游基础模型,从多交易所、多品种、多周期的金融数据中自主学习全局模式,再通过下游微调优化特定交易策略,减少传统流水线的人工成本。论文详述系统架构,包括计算基础设施、数据管理及自动化策略生成,并通过商品期货跨工具预测实验展示其效率优势。未来研究方向涵盖端到端风险建模、金融世界模拟和多粒度预测,以扩展其在低频率策略中的应用潜力。
Saizhuo Wang, Hang Yuan, Leon Zhou, Lionel M. Ni, Heung-Yeung Shum, Jian Guo* (2025)
Alpha-GPT: Human-AI Interactive Alpha Mining for Quantitative Investment.
In System Demonstrations of The 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP-2025), Suzhou, China.
本文提出Alpha-GPT——首个基于大语言模型(LLM)的人机交互式量化投资因子挖掘系统,通过知识编译-LLM推理-思想解构三层架构实现交易理念的自动化表达与优化。核心亮点包括:1)首创自然语言与量化公式的双向翻译机制,解决传统因子挖掘的语义鸿沟问题;2)集成遗传算法增强因子性能(IC提升150%+);3)构建金融知识库支持上下文学习,生成因子可解释性达专业水平。实验证明系统能精准捕捉技术形态(如金叉、布林带突破),为量化研究提供智能协作新范式。

Zhanpeng Chen, Chengjin Xu, Yiyan Qi, Jian Guo* (2025) MLLM Is a Strong Reranker: Advancing Multimodal Retrieval-augmented Generation via Knowledge-enhanced Reranking and Noise-injected Training. In Findings of The 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP-2025), Suzhou, China.
本文提出RagVL框架,解决多模态检索增强生成(Multimodal RAG)中的多粒度噪声对应问题。核心亮点包括:1)知识增强重排序:通过指令微调MLLM诱导其排序能力,作为重排序器精准筛选相关图像(如实验显示Recall@2提升40%)。2)噪声注入训练:在数据和令牌级别注入视觉噪声(如高斯噪声),增强生成器鲁棒性,有效缓解噪声干扰。3)高效性能:在WebQA和MultimodalQA上验证,显著提升检索精度与生成准确率(如F1提升29.75%),支持动态知识集成。
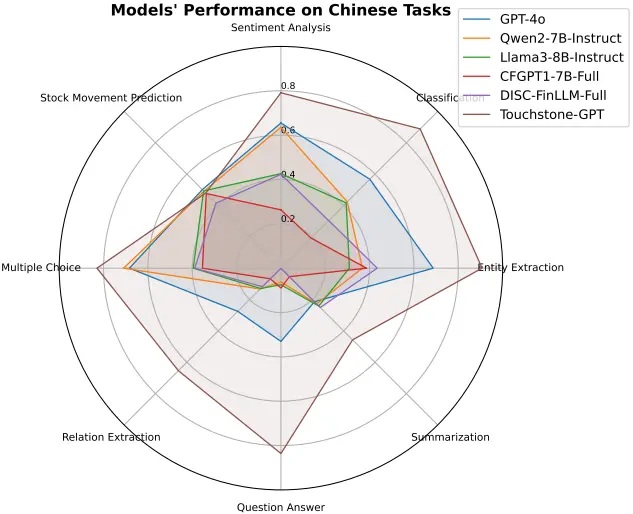
Xiaojun Wu, Junxi Liu, Huanyi Su, Zhouchi Lin, Yiyan Qi, Chengjin Xu, Jiajun Su, Jiajie Zhong, Fuwei Wang, Saizhuo Wang, Fengrui Hua, Jia Li, Jian Guo* (2025) Golden Touchstone: A Comprehensive Bilingual Benchmark for Evaluating Financial Large Language Models. In Findings of The 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP-2025), Suzhou, China.
本文提出Golden Touchstone——首个中英双语金融大模型评测基准,覆盖8类核心NLP任务(情感分析、实体识别、股价预测等),整合22个高质量数据集,解决现有基准语言单一性与任务碎片化问题。亮点包括:1)首创双语对齐评测框架,支持跨语言金融能力评估;2)系统评测GPT-4o/Llama-3/FinGPT等模型,揭示LLMs在关系抽取与股价预测等复杂任务的短板;3)开源Touchstone-GPT模型,通过领域预训练与指令微调实现多项任务SOTA。研究为金融大模型发展提供标准化工具与优化方向。

Jincai Huang, Yongjun Xu, Qi Wang, Qi (Cheems) Wang, Xingxing Liang, Fei Wang, Zhao Zhang, Wei Wei, Boxuan Zhang, Libo Huang, Jingru Chang, Liantao Ma, Ting Ma, Yuxuan Liang, Jie Zhang, Jian Guo†, Xuhui Jiang, Xinxin Fan, Zhulin An, Tingting Li, Xuefei Li, Zezhi Shao, Tangwen Qian, Tao Sun, Boyu Diao, Chuanguang Yang, Chenqing Yu, Yiqing Wu, Mengxian Li, Haifeng Zhang, Yongcheng Zeng, Zhicheng Zhang, Zhengqiu Zhu, Yiqin Lv, Aming Li, Xu Chen, Bo An, Wei Xiao, Chenguang Bai, Yuxing Mao, Zhigang Yin, Sheng Gui, Wentao Su, Yinghao Zhu, Junyi Gao, Xinyu He, Yizhou Li, Guangyin Jin, Xiang Ao, Xuehao Zhai, Haoran Tan, Lijun Yun, Hongquan Shi, Jun Li, Changjun Fan, Kuihua Huang, Ewen Harrison, Victor C.M. Leung, Sihang Qiu, Yanjie Dong, Xiaolong Zheng, Gang Wang, Yu Zheng, Yuanzhuo Wang, Jiafeng Guo, Lizhe Wang, Xueqi Cheng, Yaonan Wang, Shanlin Yang, Mengyin Fu, Aiguo Fei (2025) Foundation Models and Intelligent Decision-making: Progress, Challenges, and Perspectives. The Innovation, Volume 6, Issue 6.
注:本文被Cell子刊The Innovation选为第6卷第6期封面文章。
智能决策从规则驱动、数据驱动迈向生成智能的新纪元,基础模型(Foundation model)的崛起为这一变革注入核心动力。整合文本、图像、传感器等多模态数据显著提升决策效率与精度,而生成式AI更为面向决策的超级智能提供可能。这篇Review文章系统性的梳理了智能决策的演进脉络,解析基础模型如何赋能智能决策并广泛应用于医疗、金融、交通等关键领域,进一步深入探讨其机遇、风险与挑战。
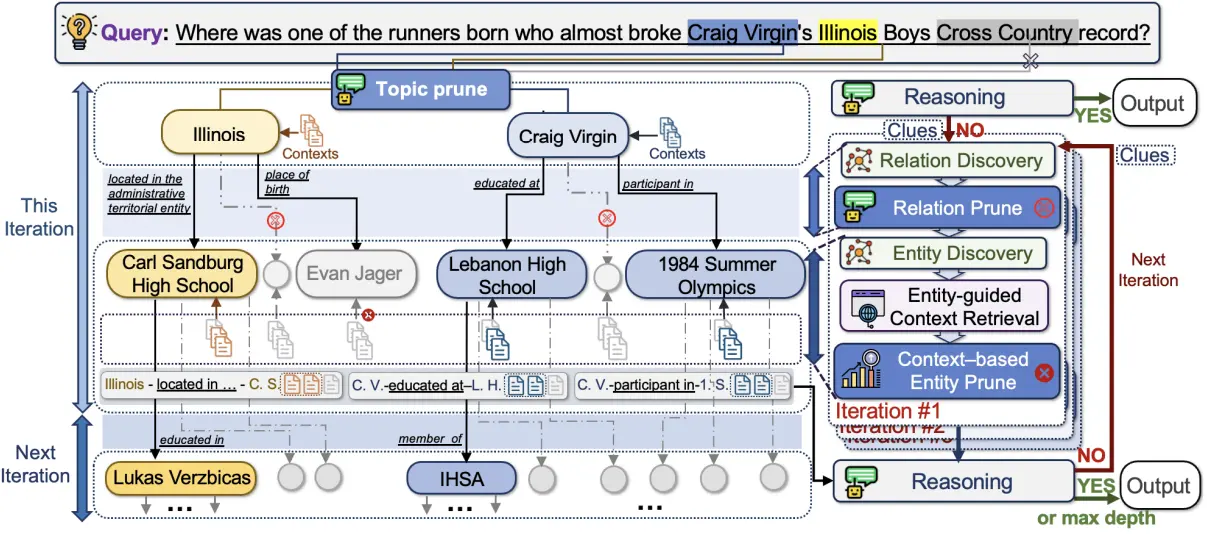
Shengjie Ma, Chengjin Xu, Xuhui Jiang, Muzhi Li, Huaren Qu, Cehao Yang, Jiaxin Mao, Jian Guo* (2025) Think-on-Graph 2.0: Deep and Faithful Large Language Model Reasoning with Knowledge-guided Retrieval Augmented Generation. In Proceedings of 2025 International Conference on Learning Representations (ICLR-2025), Singapore.
针对大模型RAG搜索深度和完整度不佳问题,本文提出了新一代思维图谱技术Think-on-Graph2.0,利用知识图谱的知识骨架优势提升RAG信息搜索的深度和广度,显著提升了知识推理的质量,在至少6个知识推理任务中取得SOTA。
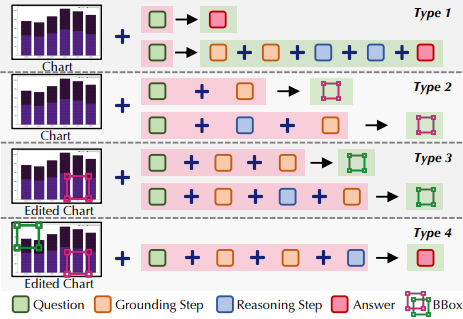
Zhengzhuo Xu, SiNan Du, Yiyan Qi, SiwenLu, Chengjin Xu, Chun Yuan, Jian Guo* (2025) ChartPoint: Guiding MLLMs with Grounding Reflection for Chart Reasoning. In Proceedings of 2025 International Conference on Computer Vision (ICCV-2025), Honolulu, Hawaii, USA.
这篇论文提出PointCoT框架,通过生成边界框与图表重渲染机制,强制MLLM在推理中关联文本步骤与视觉元素,解决其依赖OCR导致的数值幻觉问题。研究构建含19.2K样本的ChartPoint-SFT-62k数据集,集成逐步推理、关键位置标注及可视化修正,基于Qwen2-VL微调出ChartPointQ2/Q2.5模型。在ChartQA和ChartBench基准测试中,模型较现有技术显著提升,尤其在文本标注稀疏场景下实现5.04%的性能增益,为复杂图表推理提供新范式。
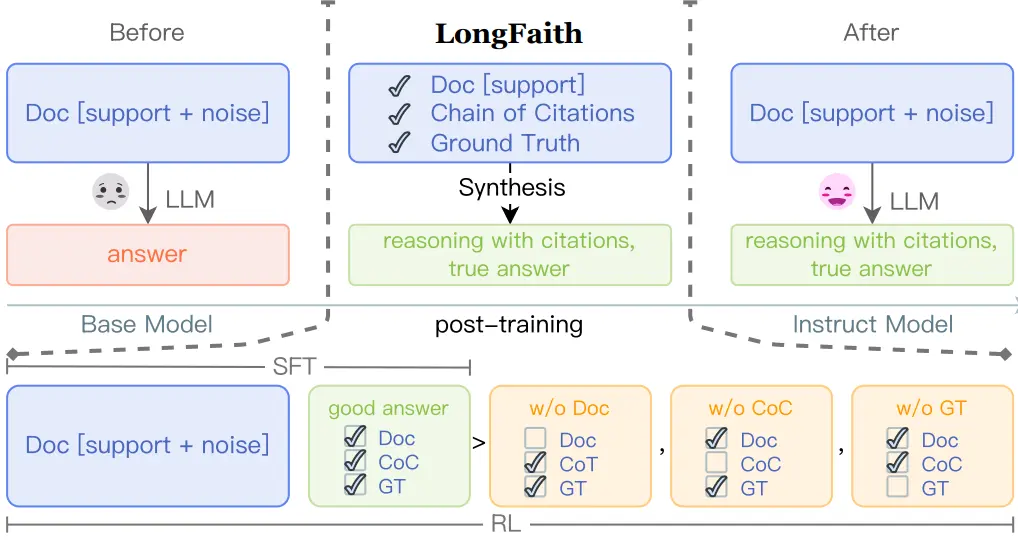
Cehao Yang, Xueyuan Lin, Chengjin Xu, Xuhui Jiang, Shengjie Ma, Aofan Liu, Hui Xiong, Jian Guo* (2025) LongFaith: Enhancing Long-Context Reasoning in LLMs with Faithful Synthetic Data. The 63rd Annual Meeting of the Association for Computational Linguistics (ACL2025), Vienna, Austria.
本文提出LongFaith方法,通过结合真实答案与引用链提示(Chain-of-Citation)合成高质量可信长文本推理数据(包含监督微调数据集LongFaith-SFT和偏好优化数据集LongFaith-PO),有效解决了现有合成数据中因缺乏验证、无引用标注和知识冲突导致的错误问题,显著提升了大语言模型在长文本问答与推理任务中的性能。
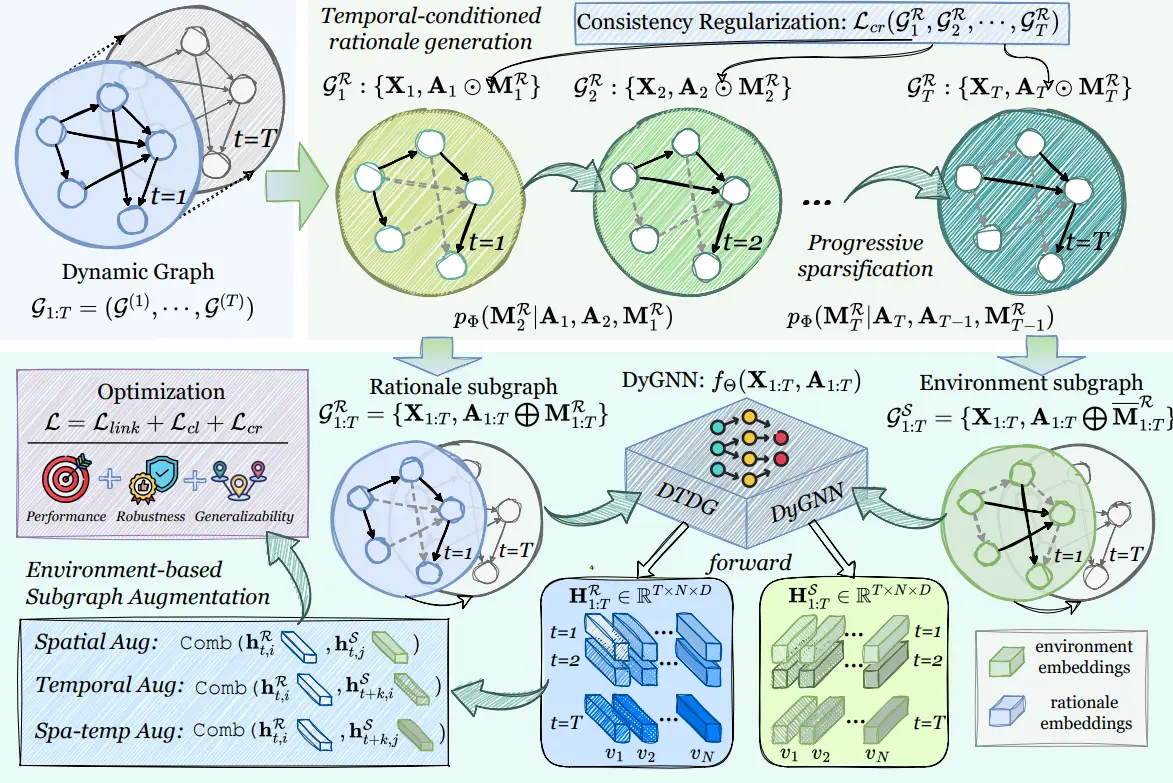
Guibin Zhang, Yiyan Qi, Ziyang Cheng, Yanwei Yue, Dawei Cheng, Jian Guo* (2025) Rationalizing and Augmenting Dynamic Graph Neural Networks. In Proceedings of 2025 International Conference on Learning Representations (ICLR-2025), Singapore.
针对动态图分析建模,本文提出时间感知的动态图增强框架DyAug,通过因果子图分离与时空环境替换,在保持时序连贯性的前提下显著提升动态图神经网络的性能,在六个基准数据集上性能提升0.89%-3.13%,抗攻击能力提升6.2%-12.2%,时间分布偏移下更稳定,实现性能、鲁棒性、泛化能力三重提升。
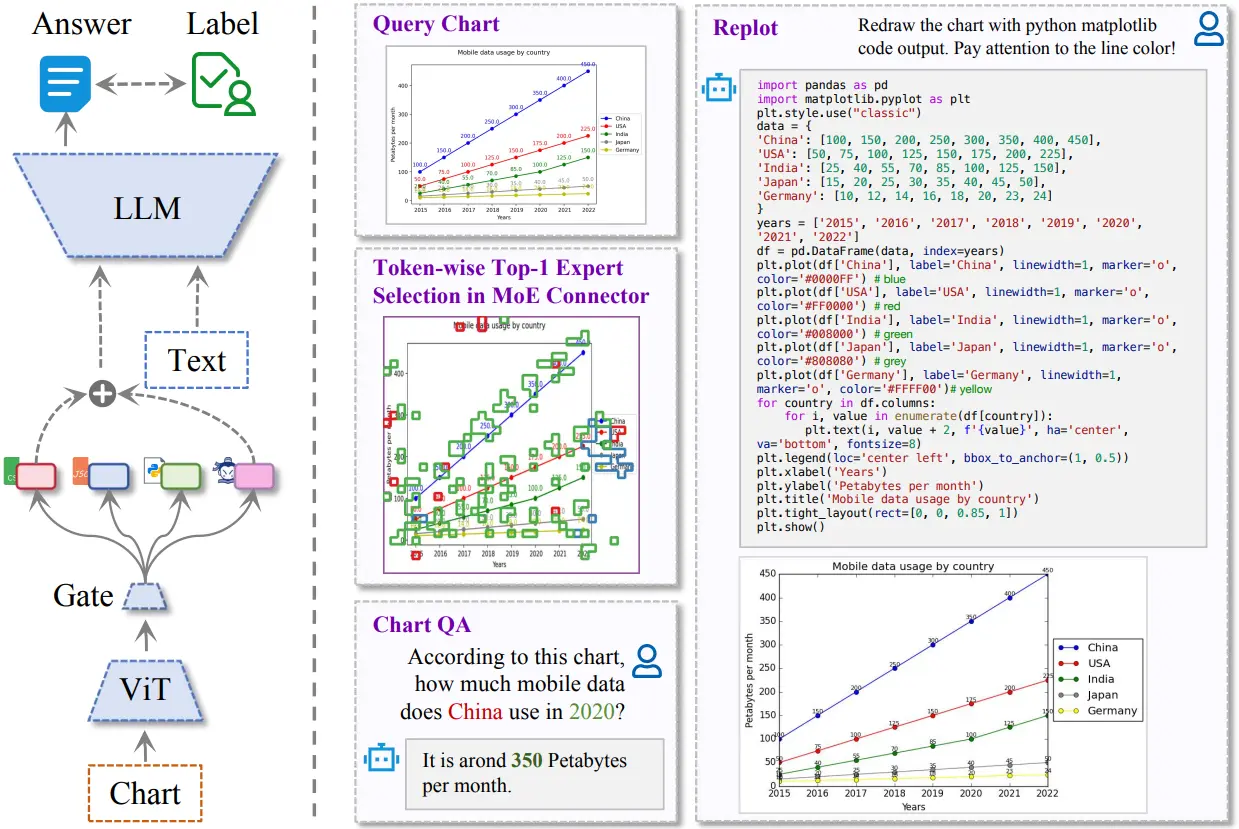
Zhengzhuo Xu, Bowen Qu, Yiyan Qi, Sinan Du, Chengjin Xu, Chun Yuan, Jian Guo* (2025) ChartMoE: Mixture of Diversely Aligned Expert Connector for Chart Understanding. In Proceedings of 2025 International Conference on Learning Representations (ICLR-2025), Singapore.
ChartMoE提出基于多样化专家初始化的MoE连接器架构,通过图表-表格/JSON/代码三重对齐任务注入异构先验知识,在保持通用能力的同时显著提升图表理解的精确性(ChartQA基准提升4.16%至84.64%),并构建百万级ChartMoE-Align数据集支持多维度对齐训练。
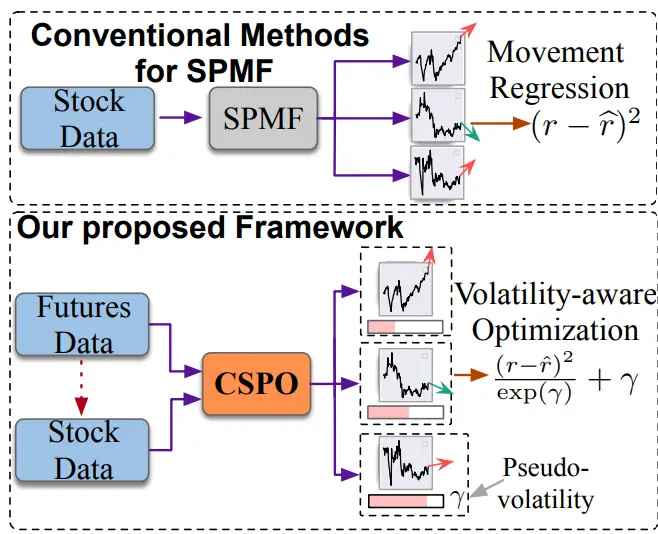
Sida Lin, Yankai Chen, Yiyan Qi, Chenhao Ma, Bokai Cao, Yifei Zhang, Xue Liu, Jian Guo* (2025) CSPO: Cross-Market Synergistic Stock Price Movement Forecasting with Pseudo-volatility Optimization. In Proceedings of The Web Conference 2025 (WWW-2025), Sydney, Australia.
本文提出一种跨市场量化投资模型,通过跨市场协同机制与伪波动优化技术显著提升股票价格预测性能。提出一种双层Transformer架构BDP-Former,通过跨市场嵌入层和价格预测层来融合期货与股票数据并捕捉市场间动态关联,同时引入贝叶斯伪波动估计器建模个股预测置信度。回测显示该模型在CSI300指数上实现年化收益提升7.15%,公开基准IC指标最高提升56.1%,验证了跨市场信息融合与波动感知优化的协同有效性。
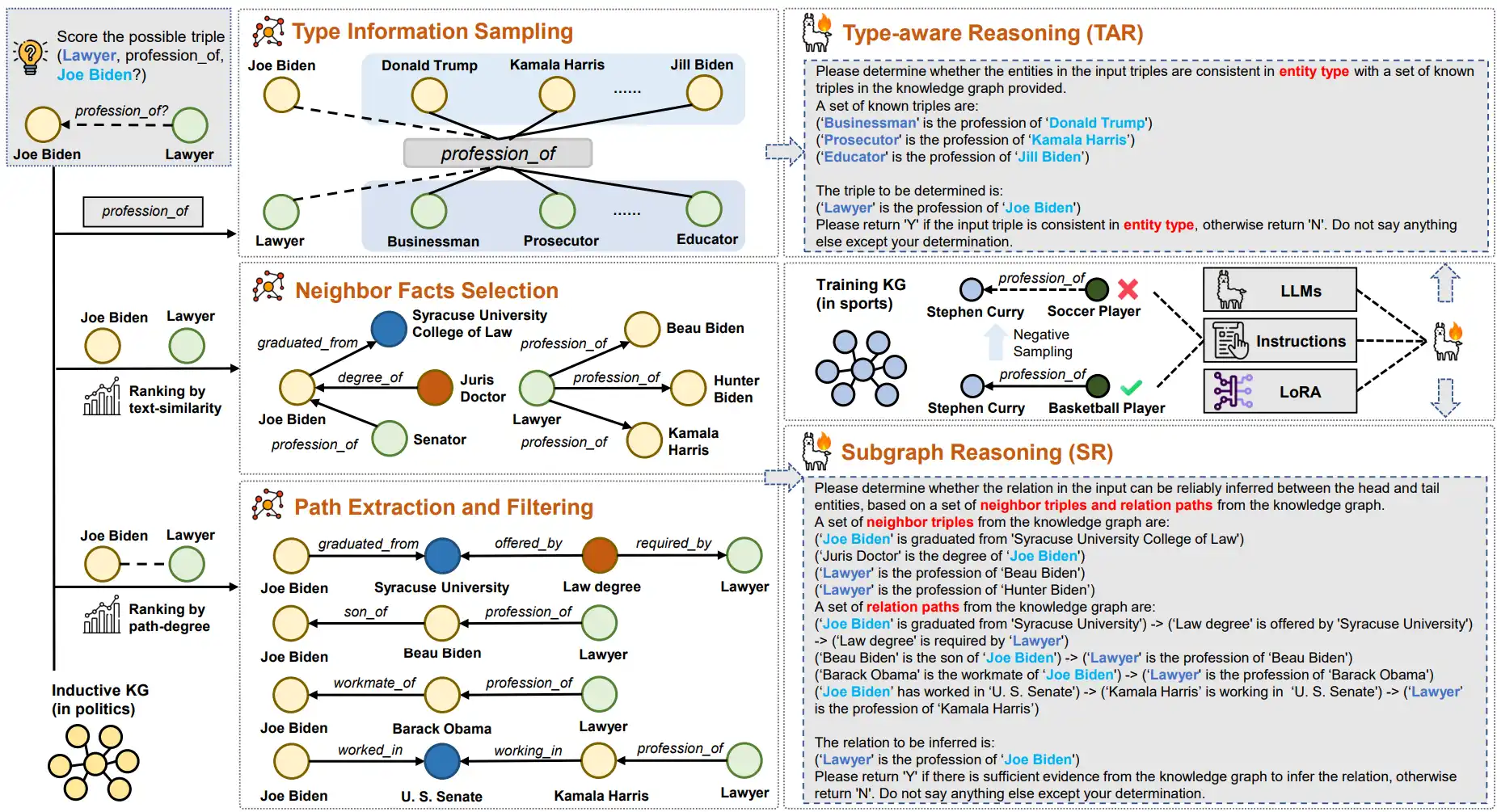
Muzhi Li, Cehao Yang, Chengjin Xu, Zixing Song, Xuhui Jiang, Jian Guo*, Ho-fung Leung, Irwin King (2025) Context-aware Inductive Knowledge Graph Completion with Latent Type Constraints and Subgraph Reasoning. In Proceedings of The 39th Annual AAAI Conference on Artificial Intelligence (AAAI-2025), Philadelphia, Pennsylvania, USA.
本文提出首个纯LLM驱动的归纳知识图谱补全框架CATS,通过双模块协同解决未见实体推理。1.类型感知推理:利用关系隐含的实体类型约束筛选候选实体;2.子图推理:融合路径语义与邻接事实增强证据支持。在18项基准中16项刷新SOTA,平均MRR提升7.2%,显著提升稀疏场景鲁棒性。
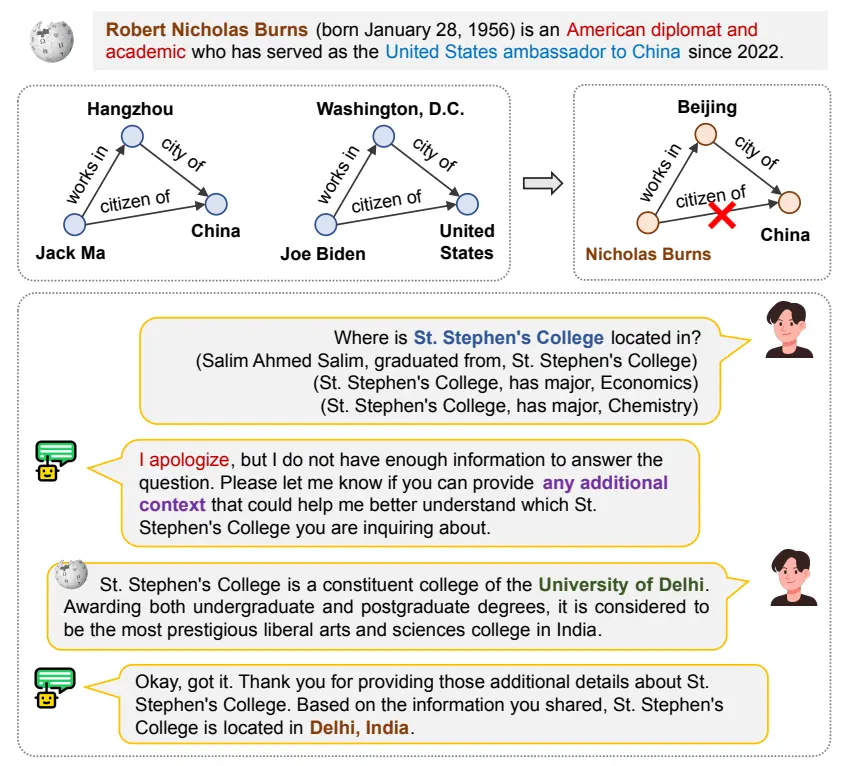
Muzhi Li, Cehao Yang, Chengjin Xu, Xuhui Jiang, Yiyan Qi, Jian Guo*, Ho-fung Leung, Irwin King. (2025) Retrieval, Reasoning, Re-ranking: A Context-Enriched Framework for Knowledge Graph Completion. In Proceedings of the 2025 Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL-2025), Albuquerque, New Mexico, USA.
知识图补全技术广泛应用于推荐系统、知识图谱等领域。本文提出KGR3框架,通过融合知识图谱三元组与来自大语言模型的更丰富的知识图节点信息,提升知识图补全精度。在FB15k237和WN18RR数据集上实现Hits@1突破性提升(12.3%/5.6%),有效弥合KG结构与自然语言语义鸿沟,兼容多种基模型且无需重新训练。
Hongwei Zhang, Saizhuo Wang, Zixin Hu, Yuan Qi, Zengfeng Huang, Jian Guo* (2025)
I2HGNN: Iterative Interpretable HyperGraph Neural Network for Semi-Supervised Classification.
Neural Networks, Volume 183, March 2025, 106929.
超图(HyperGraph)深度学习可以广泛应用于量化投资和推荐系统等领域。本文提出一种能量最小化函数的方法来优化超图神经网络来克服传统图神经网络算法的局限,在15个图节点分类任务上展现出显著优势。
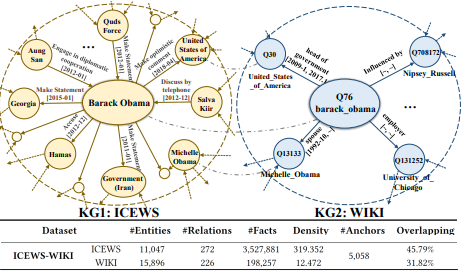
Xuhui Jiang, Chengjin Xu, Yinghan Shen, Yuanzhuo Wang, Fenglong Su, Fei Sun, Zixuan Li, Zhichao Shi, Jian Guo*, Huawei Shen (2024) Toward Practical Entity Alignment Method Design: Insights from New Highly Heterogeneous Knowledge Graph Datasets. In Proceedings of the ACM Web Conference 2024 (WWW-2024), Oral Paper. Association for Computing Machinery, New York, NY, USA, 2325–2336.
这篇论文针对知识图谱实体对齐任务中现有数据集异构性不足的问题,提出了两个高度异构数据集ICEWS-WIKI和ICEWS-YAGO(结构相似度仅14-15%,重叠率31-70%)。实验发现:在高度异构场景下,现有方法(尤其GNN模型)因结构信息难以利用而性能骤降(如Dual-AMN在ICEWS-YAGO的MRR仅0.069);通过剖析GNN机制,发现消息传递和聚合机制在异构图中会引入噪声。为此设计Simple-HHEA模型,采用特征白化、时间编码和随机游走结构编码(规避传统聚合),在ICEWS-WIKI上实现15.9%的Hits@1提升。研究指出未来方向:构建更贴近实际的数据集、开发自适应信息质量的模型架构、探索非GNN的新范式。
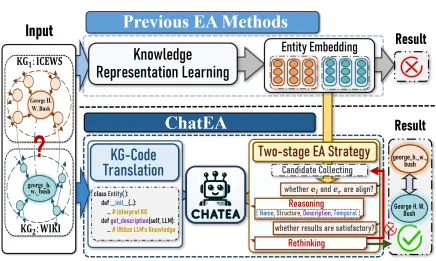
Xuhui Jiang, Yinghan Shen, Zhichao Shi, Chengjin Xu, Wei Li, Zixuan Li, Jian Guo*, Huawei Shen, Yuanzhuo Wang (2024) Unlocking the Power of Large Language Models for Entity Alignment. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7566–7583, Bangkok, Thailand.
文本提出新型知识融合技术ChatEA,融合大语言模型(LLM)与知识表示学习,通过KG-code模块激活LLM的外部知识,并设计两阶段对齐策略(候选收集+推理反思),在高度异构知识图谱上实现Hits@1指标9%-16%的提升,突破传统实体对齐方法的局限性。
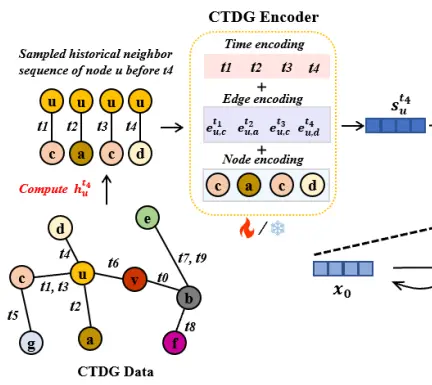
Yuxing Tian, Yiyan Qi, Aiwen Jiang, Qi Huang, Jian Guo* (2024) Latent Diffusion-based Data Augmentation for Continuous-Time Dynamic Graph Model. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2024), Association for Computing Machinery, New York, NY, USA, 2900–2911.
连续时间动态图可用于横截面量化选股、推荐系统、金融反欺诈等领域。本文提出Conda,一种基于变分自编码器(VAE)和条件扩散模型(Conditional Diffusion Model)的隐空间数据增强算法框架,通过生成高质量的嵌入数据,无需领域知识即可提升7种连续时间动态图模型性能,在稀疏数据场景下最高提升5%的链路预测准确率。
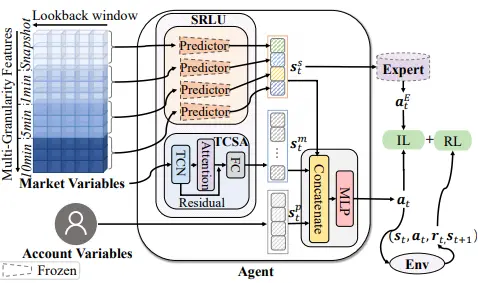
Hui Niu, Siyuan Li, Jiahao Zheng, Zhouchi Lin, Bo An, Jian Li, Jian Guo* (2024) IMM: An Imitative Reinforcement Learning Approach with Predictive Representation Learning for Automatic Market Making. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI2024), Pages 5999-6007, Jeju, South Korea.
传统高频做市策略因单价格层级设计和频繁撤单导致队列优先级信息丢失。本文提出IMM框架,结合稳定参考价编码多多价位交易订单、预测信号驱动的状态表征学习(TCSA网络)及专家模仿强化学习,建模多价位动作空间并利用模仿学习优化探索效率,在4个期货市场实现风险调整收益最高提升2.7倍,显著降低做市策略的逆向选择风险。

Xuhui Jiang, Yinghan Shen, Zhichao Shi, Chengjin Xu, Wei Li, Huang Zihe, Jian Guo* and Yuanzhuo Wang (2024) MM-ChatAlign: A Novel Multimodal Reasoning Framework based on Large Language Models for Entity Alignment. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 2637–2654, Miami, Florida, USA.
背景:传统多模态实体对齐(MMEA)方法依赖嵌入表示,存在视觉属性理解不足和跨模态语义鸿沟问题;核心思想:提出MM-ChatAlign框架,结合大语言模型(MLLM)的视觉推理能力与嵌入候选集筛选,通过两阶段推理(描述生成+概率重评估)实现对齐;创新点:MMKG-Code翻译模块将知识图转化为LLM可理解代码,动态候选集扩展策略提升效率;效果:在四个MMEA数据集上Hits@1最高提升22.5%(如ICEWS-WIKI达0.945),缓解跨模态语义鸿沟。

Jiashuo Sun, Yi Luo, Yeyun Gong, Chen Lin, Yelong Shen, Jian Guo*, Nan Duan (2024) Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models. In Findings of the Association for Computational Linguistics: NAACL 2024, pages 4074–4101, Mexico City, Mexico. Association for Computational Linguistics.
提出Iter-CoT方法,通过迭代自修正机制让大语言模型自动优化推理链错误,并筛选“有挑战但可解”的示例作为学习样本,显著提升复杂问题解答能力——在10个数学/常识/符号推理数据集上平均准确率提升9.5%(最高达17%),无需人工标注推理过程。
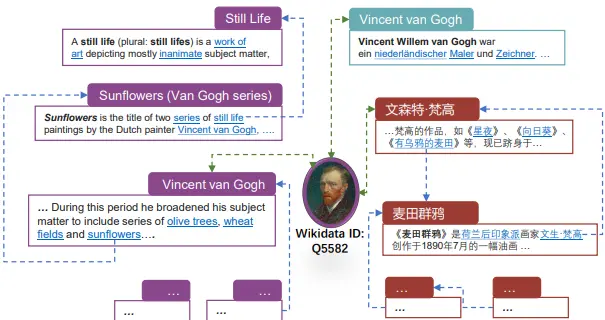
Hang Zhang, Yeyun Gong, Dayiheng Liu, Shunyu Zhang, Xingwei He, Jiancheng Lv, Jian Guo* (2024) Knowledge Enhanced Pre-training for Cross-lingual Dense Retrieval. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 9810–9821, Torino, Italia.
本文提出KEPT模型,通过挖掘维基百科的跨语言知识构建高质量训练样本,KEPT模型用同语言内对称超链接的文本段作为正样本对(比如“梵高”页面和“向日葵”页面互相链接)并用多语言实体描述作为跨语言正样本对(比如中英文的“梵高”词条)。显著提升跨语言稠密检索性能,在三个基准测试中取得SOTA。
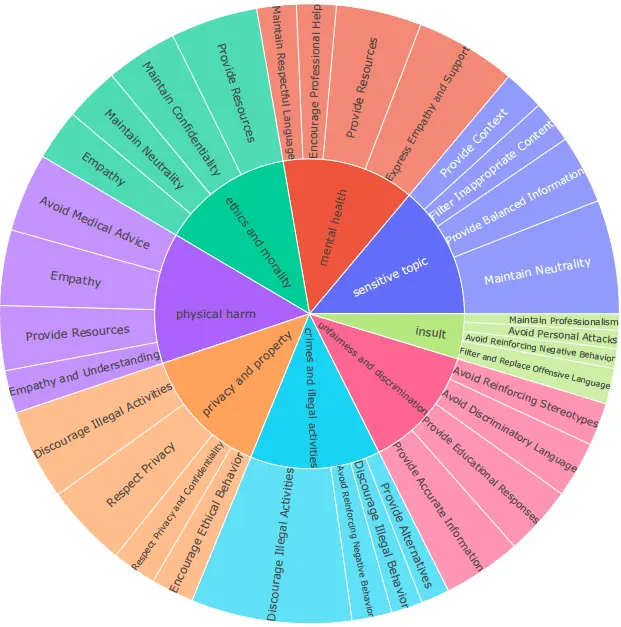
Yi Luo, Zhenghao Lin, YuHao Zhang, Jiashuo Sun, Chen Lin, Chengjin Xu, Xiangdong Su, Yelong Shen, Jian Guo*, Yeyun Gong (2024) Ensuring Safe and High-Quality Outputs: A Guideline Library Approach for Language Models. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 1152–1197, Mexico City, Mexico. Association for Computational Linguistics.
本文提出 Guide-Align框架,通过安全训练的大模型(如GPT-3.5)自动生成细粒度指南库(33k条),训练轻量检索模型为输入匹配安全/质量指南,引导LLM生成对齐人类价值观的响应。微调得到的Labrador(13B参数)在三大安全基准(Do_Not_Answer等)上超越GPT-3.5,对齐能力优于GPT-4,显著提升模型安全性与输出质量。
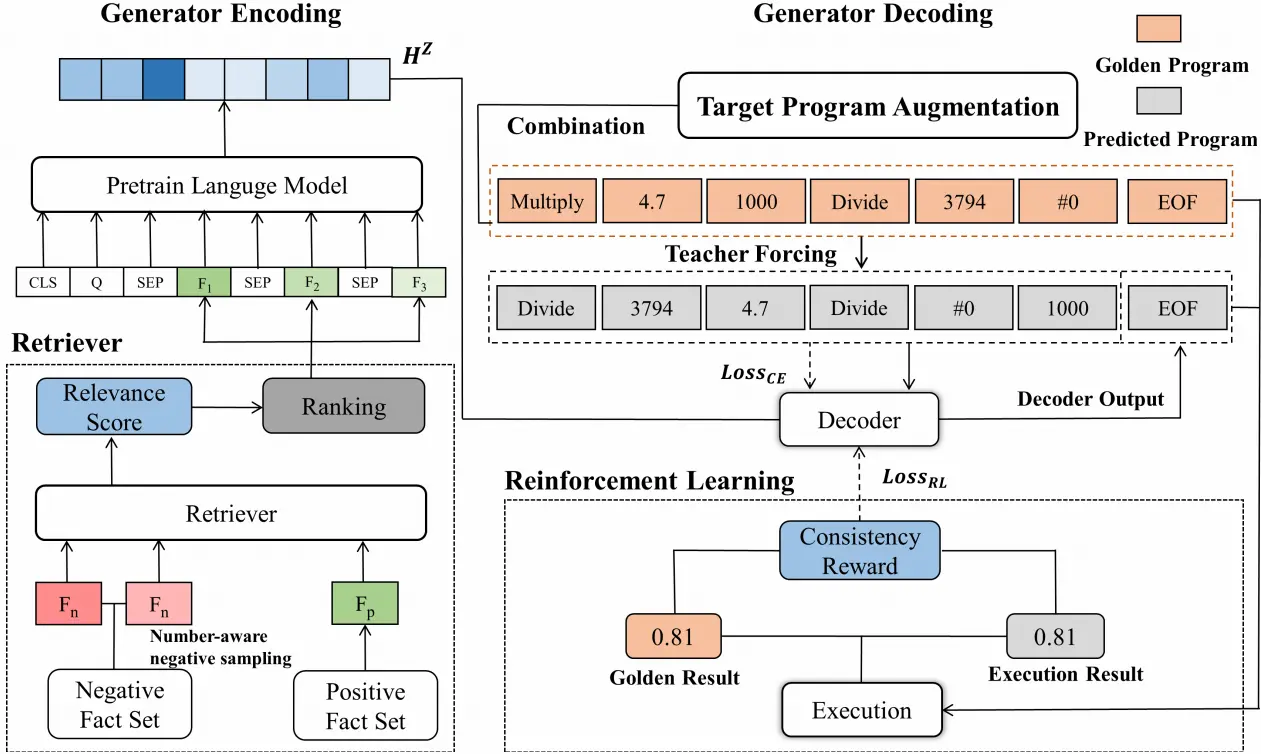
Jiashuo Sun, Hang Zhang, Chen Lin, Yeyun Gong, Jian Guo (2024) APOLLO: An Optimized Training Approach for Long-form Numerical Reasoning. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 1370–1382, Torino, Italia.
长文本数值推理能力是自然语言模型的瓶颈之一。本文提出APOLLO模型,通过数值感知负采样优化检索器(区分关键数值事实),结合目标程序增强与一致性强化学习改进生成器(解决程序表达多样性问题),显著提升长文本数值推理性能。在FinQA和ConvFinQA金融数据集上刷新SOTA(执行准确率72.47%/78.76%),超越GPT-4等基线模型

Jian Guo*, Saizhuo Wang, Lionel M. Ni, Heung-Yeung Shum (2024) Quant 4.0: Engineering Quantitative Investment with Automated, Explainable and Knowledge-driven Artificial Intelligence. Frontiers of Information Technology and Electronic Engineering, Volume 25, Issue 11.
注:本文被Frontiers of Information Technology and Electronic Engineering期刊选为第25卷第11期封面文章。
这篇Perspective文章在回顾了过去数十年量化投资研究演化的基础上,提出了新一代量化投资研究范式Quant4.0,展望了人工智能技术对量化投资研究的影响,指出自动化AI、可解释AI和知识驱动AI的发展对量化投资研究的重要性,并提出了基于Quant4.0范式的系统架构技术路线,最后展望了量化投资技术面临的十大挑战与可能的解决方案。
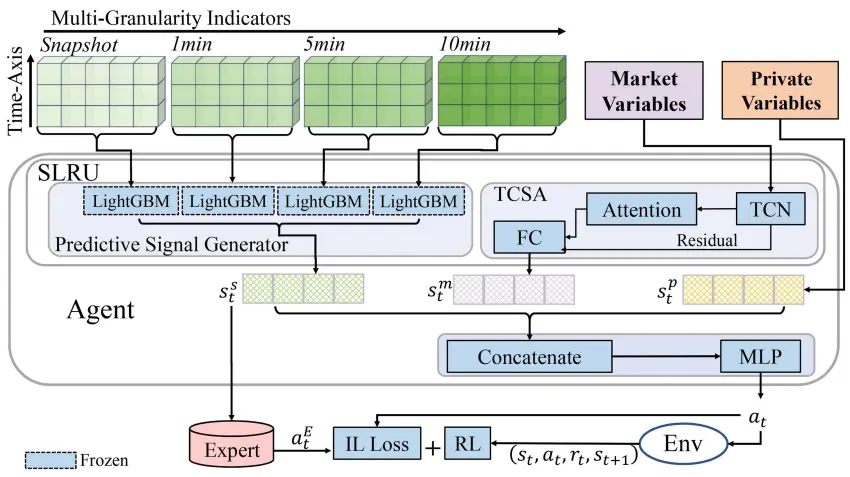
Siyuan Li, Yafei Chen, Hui Niu, Jiahao Zheng, Zhouchi Lin, Jian Li, Jian Guo, Zhen Wang (2024) Toward Automatic Market Making: An Imitative Reinforcement Learning Approach With Predictive Representation Learning. IEEE Transactions on Emerging Topics in Computational Intelligence, Volume 9, Issue 3.
本文提出一种基于强化学习的新型高频做市策略模型。与以往研究不同的是,本文模型通过构建表示学习网络挖掘交易订单簿中的多价位信息和队列信息更有效的控制了高频做市中的反向选择风险和仓位风险,并设计了专有奖励函数来控制存单风险。
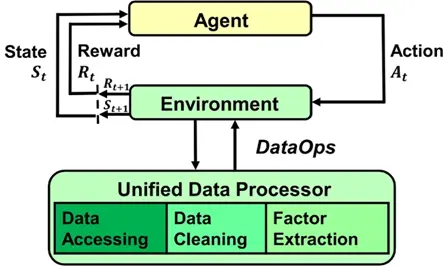
Xiao-Yang Liu, Ziyi Xia, Hongyang Yang, Jiechao Gao, Daochen Zha, Ming Zhu, Christina Dan Wang, Zhaoran Wang, Jian Guo* (2024) Dynamic Datasets and Market Environments for Financial Reinforcement Learning. Machine Learning, Volume 113, Issue 5.
对金融证券交易的高精度模拟对量化投资、金融政策制定等有重要作用,这也是世界上首个开源金融强化学习系统FinRL的使命。本文介绍了FinRL的最新研究成果FinRL-Meta,提供了对上百个真实金融交易市场的数据模拟环境,并提供了可视化云平台。开源代码可在https://github.com/AI4Finance-Foundation/FinRL-Meta下载。
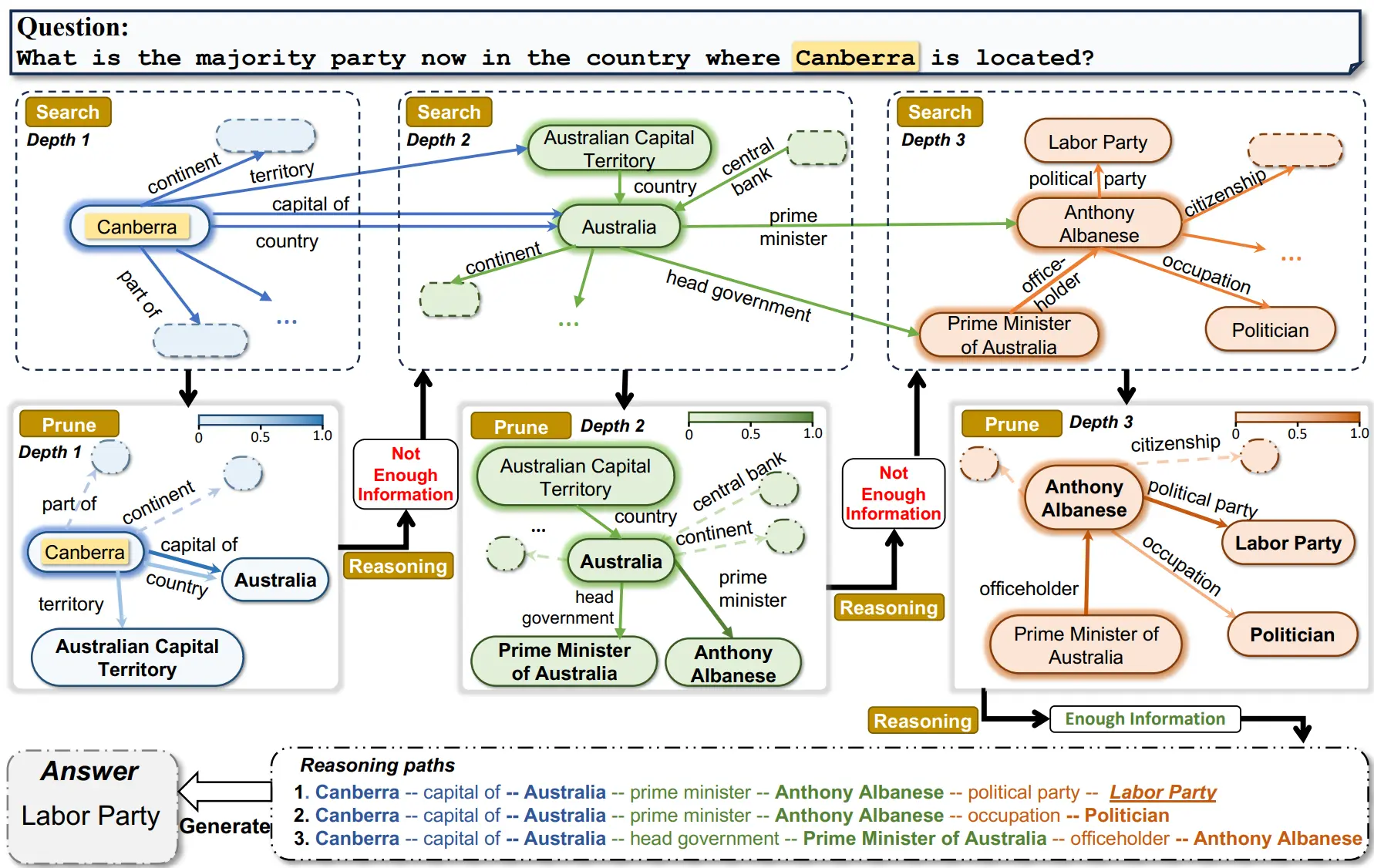
Jiashuo Sun, Chengjin Xu, Lumingyuan Tang, Saizhuo Wang, Chen Lin, Yeyun Gong, Lionel M. Ni, Heung-Yeung Shum, Jian Guo* (2024) Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph. In Proceedings of the 2024 International Conference on Learning Representations (ICLR 2024), Vienna, Austria.
注:本文研究成果“思维图谱”技术被《人民日报》等媒体报道。
幻觉(Hallucination)问题是大语言模型的一个技术瓶颈。本文提出“思维图谱(Think-on-Graph)”技术,融合大语言模型与知识图谱技术,提升了知识推理的深度和准确度,并实现了知识推理的可信可追溯可编辑。思维图谱在多个知识图谱任务中达到SOTA。
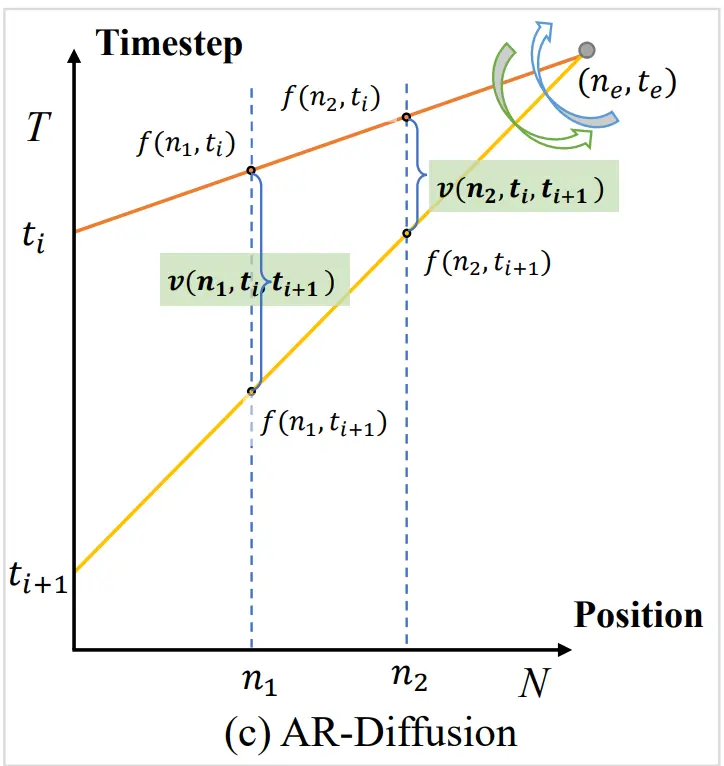
Tong Wu, Zhihao Fan, Xiao Liu, Yeyun Gong, Yelong Shen, Jian Jiao, Hai-Tao Zheng, Juntao Li, Zhongyu Wei, Jian Guo*, Nan Duan, Weizhu Chen (2023) AR-Diffusion: Auto-Regressive Diffusion Model for Text Generation. The Thirty-seventh Annual Conference on Neural Information Processing Systems (NeurIPS 2023).
AR-Difussion提出首个自回归扩散文本生成模型,通过位置相关的动态去噪机制解决语言顺序依赖问题:左侧token以更少步数先完成生成,右侧token依赖左侧信息渐进解码。结合多级扩散策略与跳跃推理机制,在摘要/翻译/常识生成任务中超越现有扩散模型,速度提升100-600倍(如3步推理质量≈GENIE的2000步),同时保持生成多样性与质量。
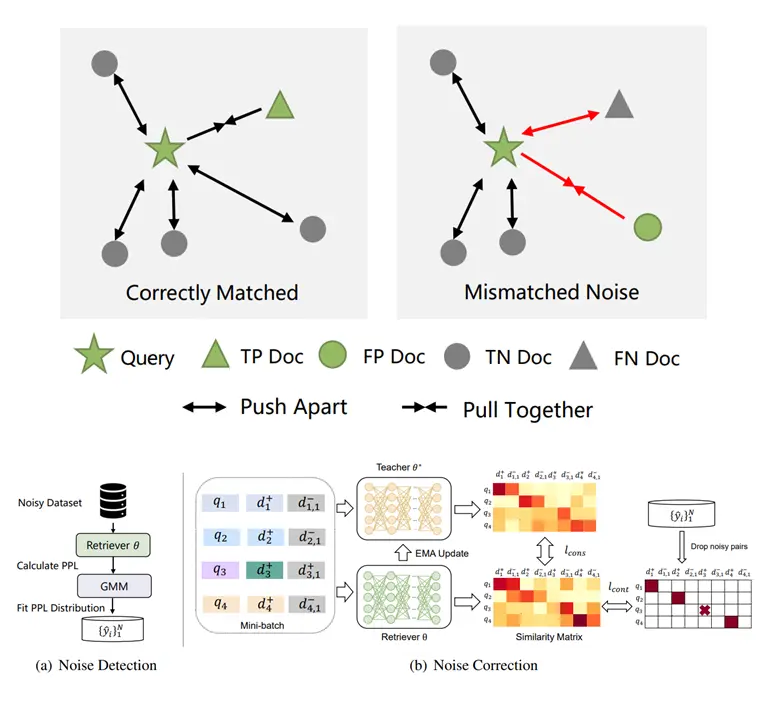
Hang Zhang, Yeyun Gong, Xingwei He, Dayiheng Liu, Daya Guo, Jiancheng Lv, Jian Guo (2023) Noisy Pair Corrector for Dense Retrieval. EMNLP 2023.
NPC提出针对稠密检索中训练数据噪声的解决方案:通过困惑度计算(易负样本与标注正样本对比)检测噪声对,利用EMA模型生成软标签校正噪声。该方法在自然问题/TriviaQA(合成噪声)和代码检索数据集StaQC/SO-DS(真实噪声)上显著提升效果,尤其在高噪声比例下性能超越基线模型10+点,验证了噪声处理的通用性与鲁棒性。
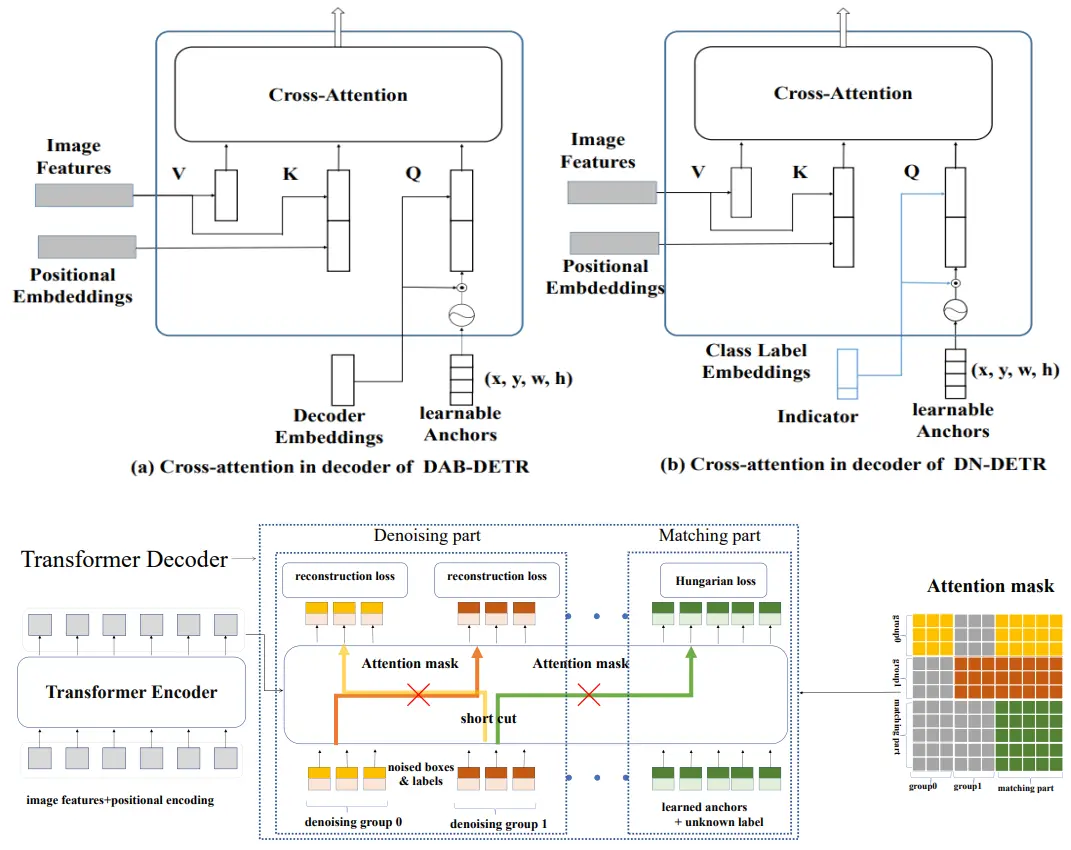
Feng Li, Hao Zhang, Shilong Liu, Jian Guo, Lionel M. Ni, Lei Zhang (2022) DN-DETR: Accelerate DETR Training by Introducing Query DeNoising. In the Proceedings of The IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR 2022), pp.13609--13617, New Orleans, LA, USA. A more comprehensieve version is published in the journal IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 46(4).
DN-DETR针对DETR训练收敛慢的问题,提出查询去噪机制:向解码器输入带噪声的真实框作为辅助查询,训练模型重构原始边界框。该设计绕过二分图匹配的不稳定性,显著加速训练(12轮达46AP,提速2倍),在COCO检测任务上比基线提升1.9AP。方法可无缝集成到DETR变体、CNN检测器(Faster R-CNN)及分割模型(Mask2Former),后续被DINO等模型采纳为关键训练技术。
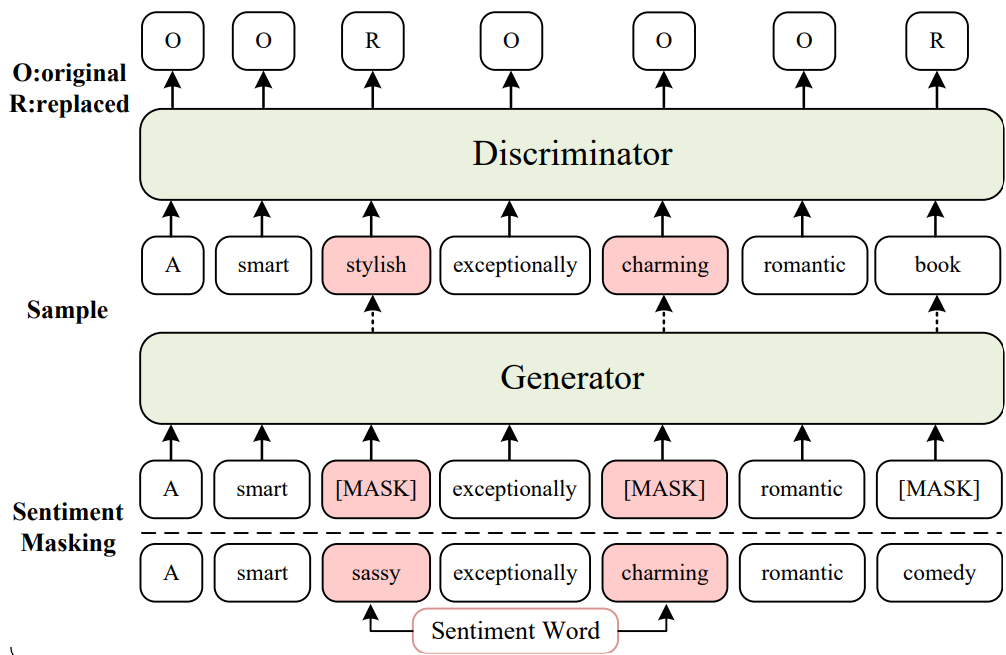
Shuai Fan, Chen Lin, Haonan Li, Zhenghao Lin, Jinsong Su, Hang Zhang, Yeyun Gong, Jian Guo, Nan Duan (2022) Sentiment-Aware Word and Sentence Level Pre-training for Sentiment Analysis. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP-2022), pages 4984–4994, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
这篇论文提出了SentiWSP模型,通过联合词级与句级情感感知预训练提升情感分析性能:在词级预训练中,采用生成器-判别器框架(如图1左侧),针对50%情感词进行掩蔽替换检测,强化情感词汇理解;在句级预训练中,通过掩蔽70%情感词构建查询句(如图1右侧),结合原始句作为正样本,并利用跨批次近似最近邻(ANCE)挖掘难负样本进行对比学习,增强句子情感编码。实验显示,SentiWSP-large在SST-5、IMDB等5个句子级任务及Restaurant14等2个方面级任务上均刷新SOTA(如MR准确率92.41%),较ELECTRA提升1.6%,并通过消融实验验证了跨批次负采样(k=7时效果最佳)和70%情感词掩蔽率的有效性。
Xiao-Yang Liu, Ziyi Xia, Jingyang Rui, Jiechao Gao, Hongyang Yang, Ming Zhu, Christina Dan Wang, Zhaoran Wang, Jian Guo (2022) FinRL-Meta: Market Environments and Benchmarks for Data-Driven Financial Reinforcement Learning. In Proceedings of the Thirty-sixth Conference on Neural Information Processing Systems (NeurIPS-2022).
FinRL-Meta是由AI4Finance社区维护的开源库,旨在解决金融强化学习三大挑战:金融数据低信噪比、历史数据生存偏差及回测过拟合。其核心采用DataOps范式构建自动化管道,将动态市场数据转换为数百个标准化gym-style环境,支持股票、加密货币等30+数据源统一接入与特征工程(基本面/技术指标/情感数据)。框架提供三层结构:数据层实现自动清洗与特征提取,环境层模拟交易摩擦与风险控制,智能体层兼容主流DRL算法库并复现股票交易、组合优化等基准策略。通过云端竞赛平台与课程化教程,该库在道琼斯指数交易中实现DRL策略年化收益25.9%(夏普比率1.53),为金融AI工业化提供基础设施。
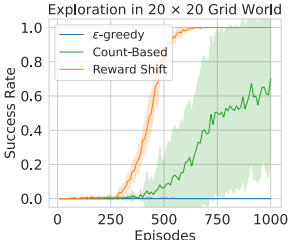
Hao Sun, Lei Han, Rui Yang, Xiaoteng Ma, Jian Guo, Bolei Zhou (2022) Exploit reward shifting in value-based deep-RL: optimistic curiosity-based exploration and conservative exploitation via linear reward shaping. In Proceedings of the Thirty-sixth Conference on Neural Information Processing Systems (NeurIPS-2022).
本文探讨奖励平移在价值型深度强化学习中的关键作用,揭示线性奖励变换等价于改变Q函数初始化:正向平移(添加正数)促进保守利用,提升离线强化学习的价值估计稳定性;负向平移(添加负数)驱动探索行为,优于传统好奇心方法。通过三类实验验证——离线RL的保守性能优化、连续控制的样本效率提升、离散任务的探索优化——该方法显著增强基线算法效果,实现探索与利用的高效平衡,且与现有技术正交,提供简单高效的通用框架。
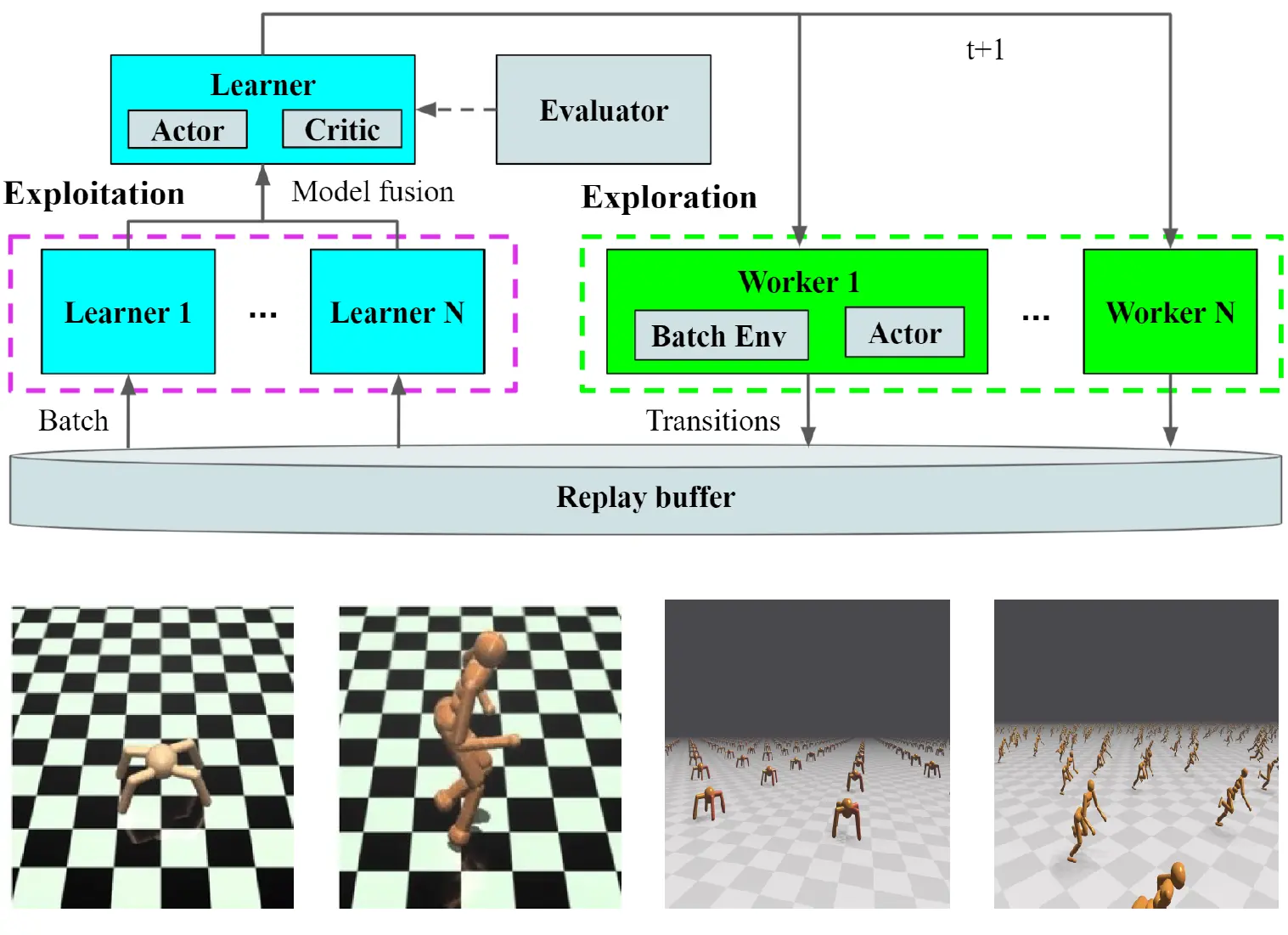
Xiao-Yang Liu, Zechu Li, Zhuoran Yang, Jiahao Zheng, Zhaoran Wang, Anwar Walid, Jian Guo, Michael Jordan. (2021) ElegantRL-Podracer: Scalable and Elastic Library for Cloud-Native Deep Reinforcement Learning. Data-Centric AI Workshop, 35th Conference on Neural Information Processing Systems (NeurIPS 2021), Sydney, Australia.
GPU-Podracer提出云原生DRL训练框架,通过多级并行机制加速数据收集:高层采用锦标赛式集成训练协调数百GPU(Leaderboard管理训练池),底层单GPU利用7000+ CUDA核心并行模拟环境交互。结合容器化与微服务实现弹性扩缩容,在NVIDIA DGX SuperPOD上验证:机器人控制任务性能超RLlib三倍,股票交易累计收益达362.4%,80 GPU时训练速度提升10倍,实现近线性扩展。
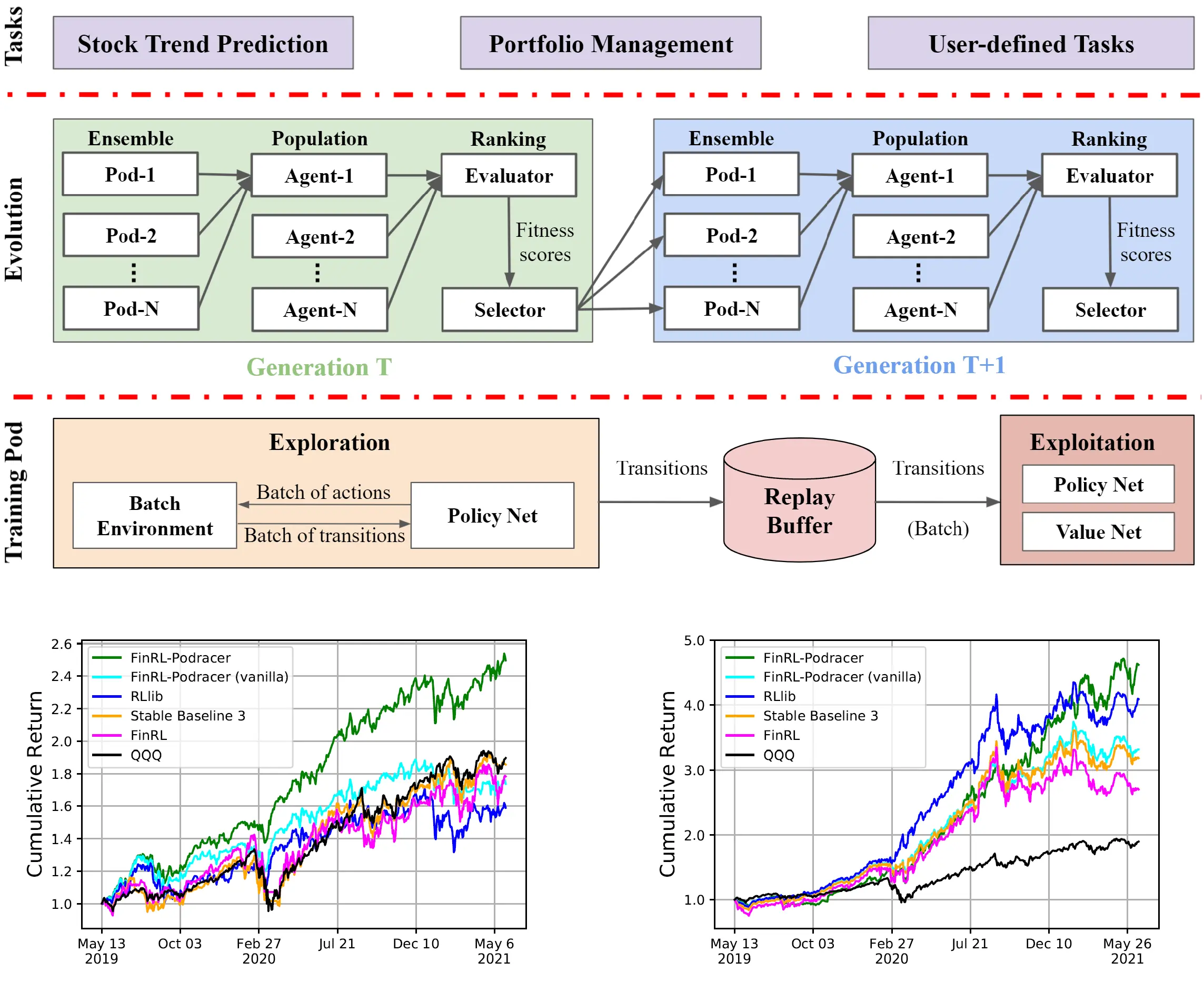
Zechu Li, Xiao-Yang Liu, Jiahao Zheng, Zhaoran Wang, Anwar Walid, Jian Guo*. (2021) FinRL-Podracer: High Performance and Scalable Deep Reinforcement Learning for Quantitative Finance. 2nd ACM International Conference on AI in Finance (ICAIF'21), November, 2021, Virtual Event, USA
FinRL-Podracer提出金融RLOps范式,结合云原生架构与代际进化机制:底层通过GPU加速环境模拟(分钟级数据吞吐)、参数通信优化实现高性能训练;中层采用评估器-选择器协同进化解决过拟合问题。在80块A100 GPU的DGX SuperPOD上,10分钟完成NASDAQ-100十年分钟级数据训练,回测年化收益111.5%,夏普比率2.42,训练速度超RLlib等基线3-7倍,收益提升12%-35%。
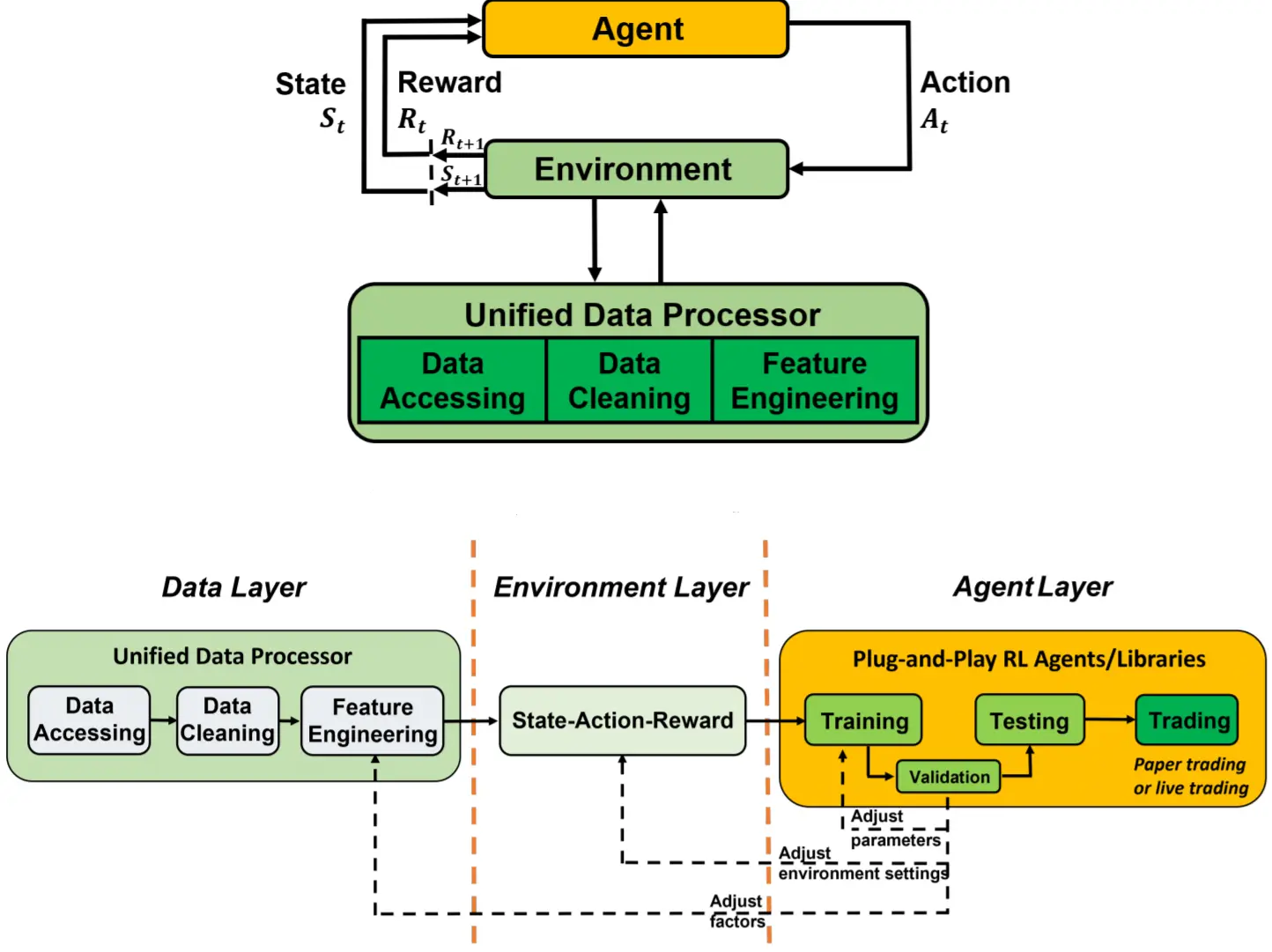
Xiao-Yang Liu, Jingyang Rui, Jiechao Gao, Liuqing Yang, Hongyang Yang, Zhaoran Wang, Christina Dan Wang, Jian Guo. (2021) FinRL-Meta: A Universe of Near-Real Market Environments for Data-Driven Deep Reinforcement Learning in Quantitative Finance. Deep RL Workshop, 35th Conference on Neural Information Processing Systems (NeurIPS 2021), Sydney, Australia.
NeoFinRL提出金融DRL框架,集成DataOps范式:分离数据处理与策略设计,提供标准化市场环境(股票、加密货币等);通过GPU并行模拟加速训练。在DJIA股票和比特币交易任务中,回测与纸交易均超越基准(加密货币年化收益360.8%,夏普比率2.99),验证框架有效性。
Qianggang Ding, Sifan Wu,, Hao Sun, Jiadong Guo and Jian Guo*. (2020) Hierarchical Multi-Scale Gaussian Transformer for Stock Movement Prediction. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI-20) Special Track on AI in FinTech, Yokohama, Japan. pp. 4640-4646.
本文提出一种面向金融时间序列预测的Transformer模型架构Hierarchical Multi-Scale Gaussian Transformer:通过多尺度高斯先验增强局部性(窗口5/10/20/40天),正交正则化减少多头冗余,交易间隔分割器分层学习日内/周特征。在NASDAQ和A股市场验证:40天窗口下准确率57.3%/58.7%,MCC 0.1146/0.1487,显著优于LSTM/ALSTM。
Ying Jin, Weilin Fu, Jian Kang, Jiadong Guo, Jian Guo*. (2020) Bayesian Symbolic Regression. The Ninth International Workshop on Statistical Relational AI at the 34th AAAI Conference on Artificial Intelligence (AAAI-2020), New York, USA
符号回归可以广泛应用于各类自动化量化投资因子挖掘任务。本文提出一种新型基于贝叶斯统计学框架的符号回归算法Bayesian Symbolic Regression (BSR) :通过线性组合多个简洁符号树提升可解释性;设计可逆跳转MCMC算法采样树结构,结合高斯先验控制复杂度。实验显示:相比传统的遗传编程(Genetic Programming)算法,BSR生成的表达式更为简洁,其表达树节点数减少40%(如f1任务22.16 vs 40.85),测试集RMSE降低50%以上(如f3任务0.21 vs 0.60),且具有更好的鲁棒性。
Jian Guo, Jie Cheng, Elizaveta Levina, George Michailidis, Ji Zhu (2015) Estimating Heterogeneous Graphical Models for Discrete Data with An Application to Roll Call Voting. Annals of Applied Statistics. 9(2): 821–848.
概率图模型在社交网络分析、股票关系分析、电商推荐等领域有广泛应用。论文提出一种基于联合估计的概率图模型用于分析多类别离散数据网络结构,并应用于美国国会投票分析:通过同步学习共同关联与类别特有关联,解析美国参议院三类议题(国防、能源、医疗)投票数据。结果显示两党共同存在党内凝聚力(如民主党更紧密),而议题特有关联揭示民主党在国防/医疗议题更团结,共和党在能源议题形成地域性联盟。较传统单独建模方法,本方法显著提升网络可解释性,分离出跨议题稳定模式与议题特异性分歧。
Jian Guo, Elizaveta Levina, George Michailidis, Ji Zhu (2015) Graphical Models for Ordinal Data. Journal of Computational and Graphical Statistics. 24(1): 183–204.
评分是各类网站和app的重要功能,通过评分来分析商品之间的关键信息和关联是概率图模型的重要功能。论文提出一种针对Ordinal型数据(如电商商品评分等)的概率图模型:假设Ordinal变量由潜在高斯分布离散化生成,其依赖结构由高斯图模型的条件相关性矩阵决定。文章设计了一种对似然函数的近似算法阿来提高EM算法(含条件期望的近似计算)的求解效率,显著降低计算复杂度。在电影评分与教育调查数据实验中,模型成功识别各类主题聚类(如科幻电影关联、教育问卷模块化结构),较baseline方法更准确的揭示了图谱实体间的关联关系和结构。
Wenqiong Xue, Jian Kang, F. DuBois Bowman, Tor D. Wager, and Jian Guo (2014) Identifying Functional Co-activation Patterns in Neuroimaging Studies via Poisson Graphical Models. Biometrics. 70(4): 812–822.
该文针对神经影像元分析中的脑区共激活计数数据,提出稀疏泊松图模型。通过多元泊松分布建模区域激活点计数的协方差结构,引入隐变量表征共激活强度,并设计带惩罚项的EM算法估计稀疏协方差矩阵(控制虚假连接)。应用于162项情绪研究,发现边缘系统-基底节共激活网络,经置换检验验证显著,且图分析揭示其小世界特性。方法较传统协方差估计偏差更低。
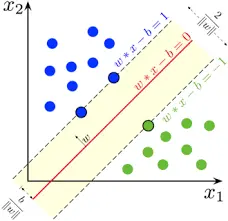
Jian Guo* (2011) Class-specific Variable Selection for Multicategory Support Vector Machines. Statistics and Its Interface. 4: 19–26.
该文针对多类别支持向量机(MSVM)提出类别特异性变量选择方法。通过引入成对融合惩罚项,强制非区分性类别的决策系数趋同,从而识别变量在特定类别间的区分性(如变量1区分类别1/2但对类别2/3无效)。在线性规划求解框架下,该方法在模拟数据与基因表达、网页分类数据中较传统方法(L1、Supnorm等)显著提升了解释性,同时保持相当预测精度,尤其在自适应融合惩罚(APF)下效果最优。

Jian Guo, Elizaveta Levina, George Michailidis, Ji Zhu (2011) Joint Estimation of Multiple Graphical Models. Biometrika. 98 (1): 1–15.
注:本文荣获2010年国际运筹与管理学会最佳学生论文奖第一名,并获得2010年美国统计学学会最佳学生论文奖。
异构概率图模型在金融学、生物信息学、自然语言等很多领域有关键应用。例如,同一组股票在不同的市场行情下有不同的关键结构和特征,同一组基因在不同的肺癌亚型中的基因调控网络有不同的结构,同一组关键词在不同的语义主题中有不同的组合形态等。然而,受限于小样本建模瓶颈,异构数据的概率图建模往往受限于每种类别中样本量不足而难以精准构建。该文针对共享变量但依赖结构部分异质的数据(如不同癌症亚型的基因网络),提出联合估计多个高斯图模型的方法。通过分层惩罚机制,在保留跨类别共同连接结构的同时,允许存在类别特异性连接。理论证明其在高维场景下具有一致性,模拟实验显示当结构重叠度高时显著优于独立建模。应用于大学网页文本挖掘,成功提取跨类别语义网络(如"research-system")及类别特有连接(如"teach-assist"仅见于学生页面)。
Bee-Chung Chen, Jian Guo, Belle Tseng, Jie Yang (2011) User Reputation in A Comment Rating Environment. Proceeding of the 17th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD-2011), San Diego, California, USA.
本文研究评论评分环境中的用户声誉问题,基于雅虎新闻等数据集发现:评论质量与用户评分几乎无关,但文本特征可高精度预测质量(接近编辑间一致性);用户评分实际反映观点支持度而非质量。为此提出新型张量模型,通过分离作者声誉、评分者偏见和观点一致性因子,从稀疏有偏数据中估计跨场景支持度声誉。实证表明该模型显著优于主流方法,并揭示去除偏见后支持度与质量相关性提升。
Liangjie Hong, Dawei Yin, Jian Guo, Brian D. Davison (2011) Tracking trends: incorporating term volume into temporal topic models. Proceeding of the 17th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD-2011), San Diego, California, USA
该文针对时间文本语料(如学术论文、新闻)中现有主题模型缺乏明确应用场景的问题,提出以“术语流量追踪”作为评估任务,即预测术语在未来时间点的出现频率。传统时间主题模型虽能捕捉主题动态演化,但未直接优化实际任务且评估困难。为此,作者设计新型监督主题模型,将术语流量作为观测变量融入状态空间框架,通过线性映射关联主题分布与术语流量,直接优化流量预测。在学术论文数据集上的实验表明,该模型显著优于自回归模型和动态主题模型(DTM),并能自然导出主题层面的流量趋势。
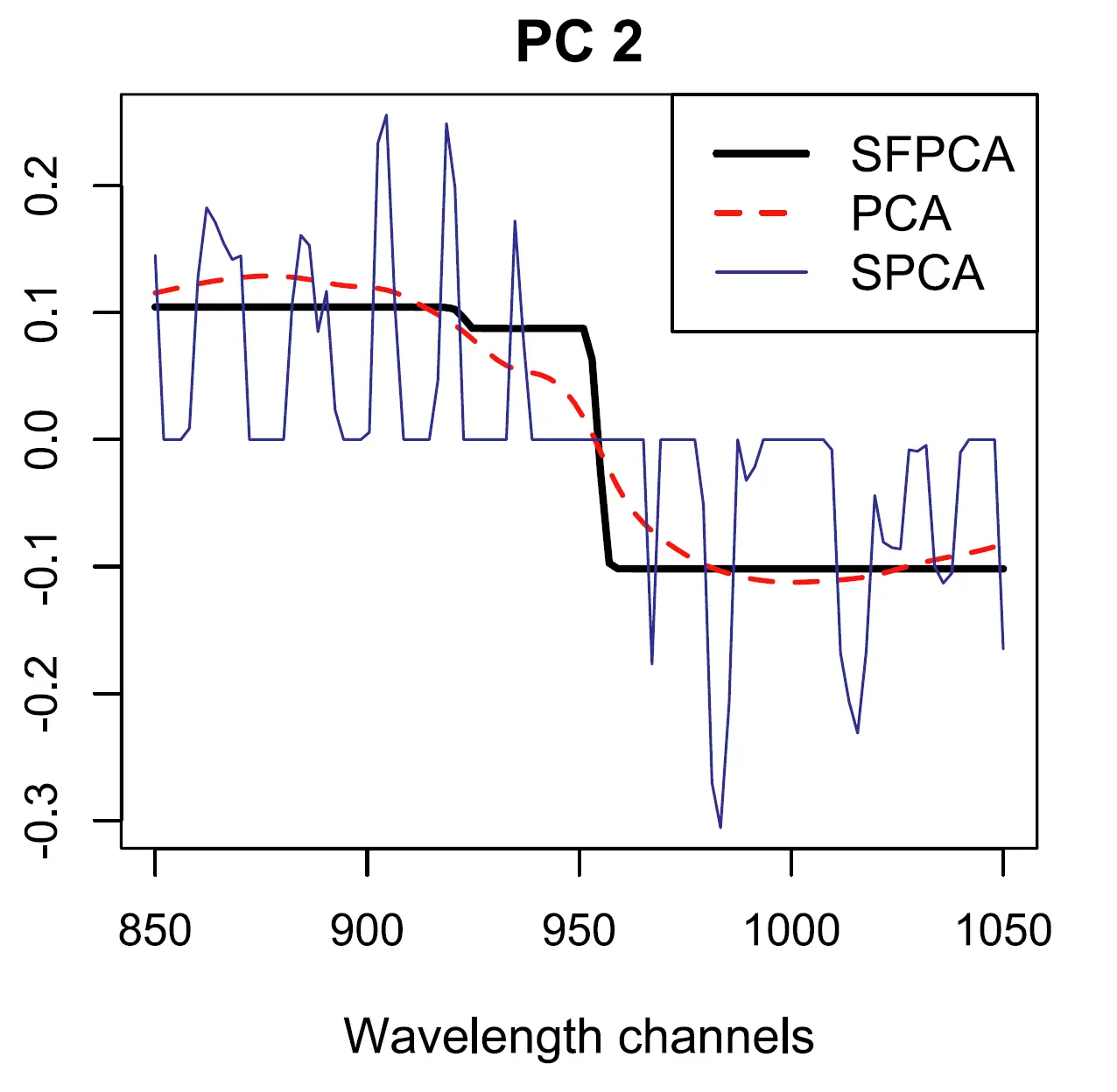
Jian Guo, Gareth James, Elizaveta Levina, George Michailidis, Ji Zhu (2010) Principal Component Analysis with Sparse Fused Loadings. Journal of Computational and Graphical Statistics. 19(4): 947–962.
该文提出了一种改进的主成分分析方法(SFPCA),通过在标准稀疏PCA模型中引入融合惩罚项,促使高度相关变量的载荷系数趋于相同幅度,从而自动识别数据中的“块状”结构。该方法不仅为不同主成分选择不同的变量子集,还能提升结果的可解释性。模拟实验和真实数据集(如光谱数据和图像数据)验证了SFPCA在揭示变量分组结构和简化解释上的有效性,优于传统稀疏PCA方法。
Jian Guo* (2010) Simultaneous variable selection and class fusion for high-dimensional linear discriminant analysis. Biostatistics. 11(4): 599–608.
针对高维基因表达数据的分类问题,本文在线性判别分析(LDA)中引入成对融合惩罚,通过自适应权重约束类间中心差异,实现同时选择重要基因并识别其可区分的具体类别。该方法解决了传统方法无法明确基因对特定类别判别能力的局限。在模拟数据和儿童肿瘤(SRBCT)及白血病(PALL)基因数据中,该方法在保持分类精度的同时,提供了更清晰的生物学解释,例如识别基因对特定癌症亚型的判别作用。
Jian Guo, Elizaveta Levina, George Michailidis, Ji Zhu (2010) Pairwise variable selection for high-dimensional model-based clustering. Biometrics. 66(3): 793–804.
注:本文的研究工作荣获2009年度美国统计学会最佳学生论文奖和2009年度国际生物统计学会杰出学生论文奖。
本文针对高维聚类问题,提出一种基于高斯混合模型的成对变量选择方法(APFP)。通过在似然函数中融入成对融合惩罚项,促使不可区分的聚类中心融合为同一值,从而同时实现变量选择和聚类特异性识别。与传统“全选或全不选”的变量选择相比,该方法能识别变量对特定聚类对的判别作用。在模拟数据和肿瘤基因表达数据中,APFP在聚类准确率、变量筛选能力和结果可解释性上均优于现有方法(如L1/L∞惩罚)。

Qiaozhu Mei, Jian Guo, Dragomir Radev (2010) DivRank: The Interplay of Prestige and Diversity in Information Networks. Proceeding of the 16th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD-2010), Washington D.C., USA. pages 1009-1018.
该论文提出了一种名为DivRank的新型网络节点排序算法,旨在平衡节点重要性与结果多样性。传统方法(如PageRank)仅基于静态转移概率衡量节点声望,导致排名靠前的节点往往来自网络同一区域、信息冗余。DivRank创新性地引入强化随机游走机制:节点被访问的次数会动态提升其转移概率,形成“富者愈富”效应。这种机制使重要节点能吸收邻居的权重,促使排名结果自动分散到不同社区。在演员网络、学术引用网络和文本摘要任务上的实验表明,DivRank在保持节点声望(如覆盖电影数、学者h指数)的同时,显著提升多样性(子图密度降低约50%),且效果优于贪心选择算法Grasshopper和传统PageRank。该算法可应用于搜索结果多样化、推荐系统等场景。
Man-Wai Mak, Jian Guo, and Sun-Yuan Kung (2008) PairProSVM: Protein Subcellular Localization Based on Local Pairwise Profile Alignment and SVM. IEEE/ACM Transactions on Computational Biology and Bioinformatics, 5 (3): 416–422.
该研究提出基于局部成对谱比对和支持向量机(SVM)的蛋白质亚细胞定位新方法PairProSVM。通过PSI-BLAST构建训练集的蛋白质谱,利用谱比对分数生成特征向量训练SVM分类器。在真核和细菌数据集上分别达到75.3%和91.9%的整体准确率,优于传统序列比对和氨基酸组成方法,且在同源性低的非冗余数据中仍保持优势。
Xian Pu, Jian Guo, Howard Leung, Yuanlie Lin (2007) Prediction of membrane protein types from sequences and position-specific scoring matrices. Journal of Theoretical Biology, 247 (2): 259–265.
本研究开发整合序列和谱的膜蛋白分类方法IAMPC。通过五个模块分别提取谱的全局/末端/分段/二肽组成特征及序列残基耦合特征,使用SVM融合输出。在2,763个膜蛋白上实现92.3%的整体准确率,与基于功能域的方法性能相当且分类优势互补。

Jian Guo, Yuanlie Lin, Xiangjun Liu (2006) GNBSL: A New Integrative System to Predict Subcellular Location for Gram-negative Bacteria Proteins. Proteomics, 6 (19): 5099–5105.
该研究针对革兰氏阴性菌提出整合谱和序列特征的亚细胞定位系统GNBSL。设计六个模块:四个从谱矩阵提取全局/局部组成特征,两个从序列提取残基耦合和局部谱比对特征,通过SVM融合预测结果。在1,302个蛋白上达到93.4%的准确率,超越PSORT-B等现有方法。
Jian Guo, Yuanlie Lin (2006) TSSub: Eukaryotic Protein Subcellular Localization by Extracting Features from Profiles. Bioinformatics, 22 (14): 1784–1785.
本论文介绍整合谱和序列特征的真核蛋白亚细胞定位系统TSSub。通过四个模块从蛋白质谱提取不同特征(全序列/N端组成、二肽组成、分段组成),第五模块从序列提取残基耦合特征,使用SVM融合五路预测结果。在基准数据集上达到93.0%的整体准确率,较单一特征方法提升显著。
Jian Guo, Xian Pu, Yuanlie Lin, Howard Leung (2006) Protein subcellular localization based on psi-blast and machine learning. Journal of Bioinformatics and Computational Biology, 4(6): 1181–1195.
该研究提出从蛋白质谱中提取特征的亚细胞定位方法。通过PSI-BLAST构建位置特异性打分矩阵,提取全序列和N端氨基酸组成特征,使用概率神经网络分类器。在两类真核数据集上分别达到89.1%和68.9%的整体准确率,优于基于氨基酸序列的传统方法,且在去冗余数据中表现更稳健。
Jian Guo, Man-Wai Mak, Sun-Yuan Kung (2006) Eukaryotic protein subcellular localization based on local pairwise profile alignment SVM. Proceedings of 2006 IEEE International Workshop on Machine Learning for Signal Processing (MLSP-2006), Maynooth, Ireland, pp. 391–396.
该论文提出了一种基于局部成对谱比对和支持向量机(SVM)的真核蛋白亚细胞定位新方法。该方法首先通过PSI-BLAST为训练集中的所有蛋白质序列生成谱(包含位置特异性打分矩阵和频率矩阵),随后计算所有序列间的成对谱比对分数作为特征向量训练SVM分类器。在测试时,查询蛋白的谱与训练集所有谱进行比对生成特征向量输入SVM预测。在Reinhardt-Hubbard数据集(2,427个真核蛋白)上的5折交叉验证显示,该方法整体准确率高达99.4%,显著优于基于序列比对(87.9%)和氨基酸组成的方法(79.4%)。特别在线粒体蛋白预测上达到98.4%的准确率。研究还发现,即使数据集中序列同源性低于5%,该方法仍能保持96%的准确率,并验证了满足Mercer条件的核函数对SVM性能的关键作用。
Jian Guo, Hu Chen, Zhirong Sun, Yuanlie Lin (2004) A novel method for protein secondary structure prediction using dual-layer SVM and profiles.. Proteins: Structure, Function and Bioinformatics, 54: 738–743.
本研究开发了基于双层SVM和位置特异性打分矩阵(PSSM)的蛋白质二级结构预测方法。利用PSI-BLAST生成PSSM谱,第一层SVM提取特征并输出预测,第二层SVM建立相邻氨基酸预测关联,以一种类似马尔可夫链的方式输出长程依赖的预测结果,提升预测准确率。在CB513数据集上实现75.2%的三态残基准确率和80.0%的片段重叠准确率,性能优于单层SVM模型。
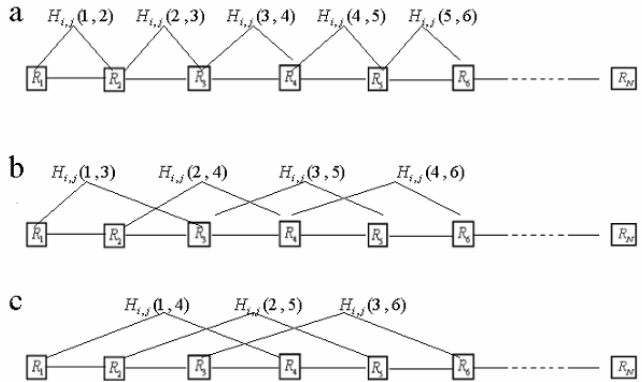
Jian Guo, Zhirong Sun (2005) Residue-couple Model for Protein Subcellular Localization Prediction.. In Proceedings of the Third Asia-Pacific Bioinformatics Conference (APBC-2005), Singapore, , pp. 117--129.
这篇论文提出了一种基于残基偶联模型和支持向量机(SVM)的蛋白质亚细胞定位预测新方法。通过定义不同秩次的残基偶联特征(如1秩捕捉相邻残基对,2秩捕捉间隔一个残基的序列模式),该模型在保留氨基酸组成信息的同时有效整合了序列顺序效应。在标准数据集上,该方法实现了原核蛋白92.0%和真核蛋白86.9%的预测准确率,较神经网路方法提升20.9%、较传统SVM方法提升7.5%,并证明对N末端序列错误具有强鲁棒性(截断40残基后真核预测精度仅降3.2%)。研究为复杂真核蛋白定位提供了更可靠的解决方案。
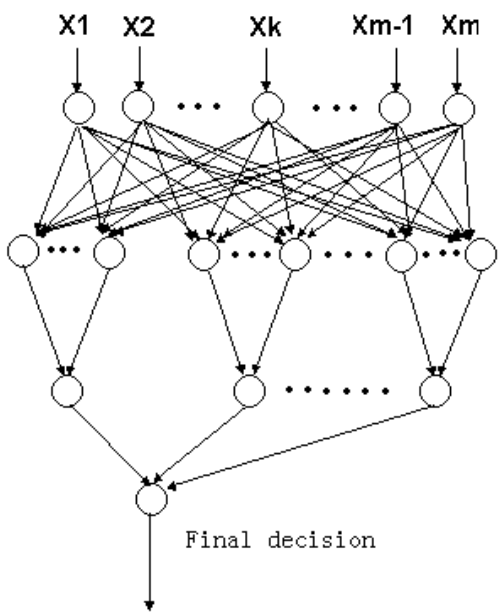
Jian Guo, Yuanlie Lin, Zhirong Sun (2004) A Novel Method for Protein Subcellular Localization Prediction Based on Boosting and Probabilistic Neural Network.. In Proceedings of the Second Asia-Pacific Bioinformatics Conference (APBC-2004), Dunedin, New Zealand, pp. 21--27.
这篇论文提出Boost-PNN方法,通过AdaBoost动态集成概率神经网络(PNN)预测蛋白质亚细胞定位。在标准数据集上实现原核蛋白92.8%、真核蛋白81.4%的准确率,较SVM提升2.0%;在新构建的8类8304蛋白数据集达83.2%。关键优势包括:对PNN平滑参数(Spread=0.01-0.05)和Boosting集规模(10%-90%训练集)强鲁棒性,且Matthews相关系数全面超越对比模型。未来将整合分选信号特征优化线粒体蛋白预测(当前61.4%准确率)。
技术报告(ArXiv Preprints)
注:*代表本人是论文通讯作者或共同通讯作者, †代表本人是论文共同第一作者
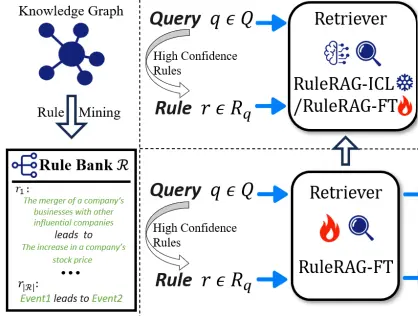
Zhongwu Chen, Chengjin Xu, Dingmin Wang, Zhen Huang, Yong Dou, Jian Guo* (2024)
RuleRAG: Rule-guided Retrieval-augmented Generation with Language Models for Question Answering.
 https://arxiv.org/abs/2410.22353.
https://arxiv.org/abs/2410.22353.
RuleRAG提出规则引导的检索增强生成框架,解决传统RAG在知识密集型问答中检索方向模糊和生成归因缺失的问题。其核心创新在于:1.双阶段规则注入:检索阶段将知识图谱(KG)提取的高置信度规则与查询拼接,引导召回逻辑相关文档;生成阶段显式引入规则作为归因依据指导推理;2.构建RuleQA基准:基于5个KG构建规则感知数据集,要求答案需规则推理而非直接复制;3.训练与泛化:RuleRAG-ICL(上下文学习)显著提升召回率89.2%和答案准确率103.1%;微调版RuleRAG-FT进一步优化,并能泛化至未见规则及ASQA等传统数据集。该方法首次系统整合规则到RAG全流程,推动可解释、强逻辑的问答系统发展。
Chengjin Xu, Muzhi Li, Cehao Yang, Xuhui Jiang, Lumingyuan Tang, Yiyan Qi, Jian Guo* (2024)
Context Graph.
https://arxiv.org/abs/2406.11160.
本文提出一种新的面向大语言模型的知识工程范式“语境图谱(Context Graph)”,以解决传统三元组知识图谱(KGs)在上下文信息缺失导致的表示和推理局限,如知识冲突和不完整性问题。CGs整合实体和关系上下文(如时间、地理位置、来源),提供更全面的知识表示。开发CGR3推理范式,利用大型语言模型(LLMs)进行检索、排序和迭代推理(流程见图3),显著提升知识图谱补全(KGC)和问答(KGQA)性能。实验在FB15k-237和YAGO3-10等数据集验证,CGR³通过上下文增强使Hits@1指标平均提升33%,证实其在复杂推理任务中的有效性。
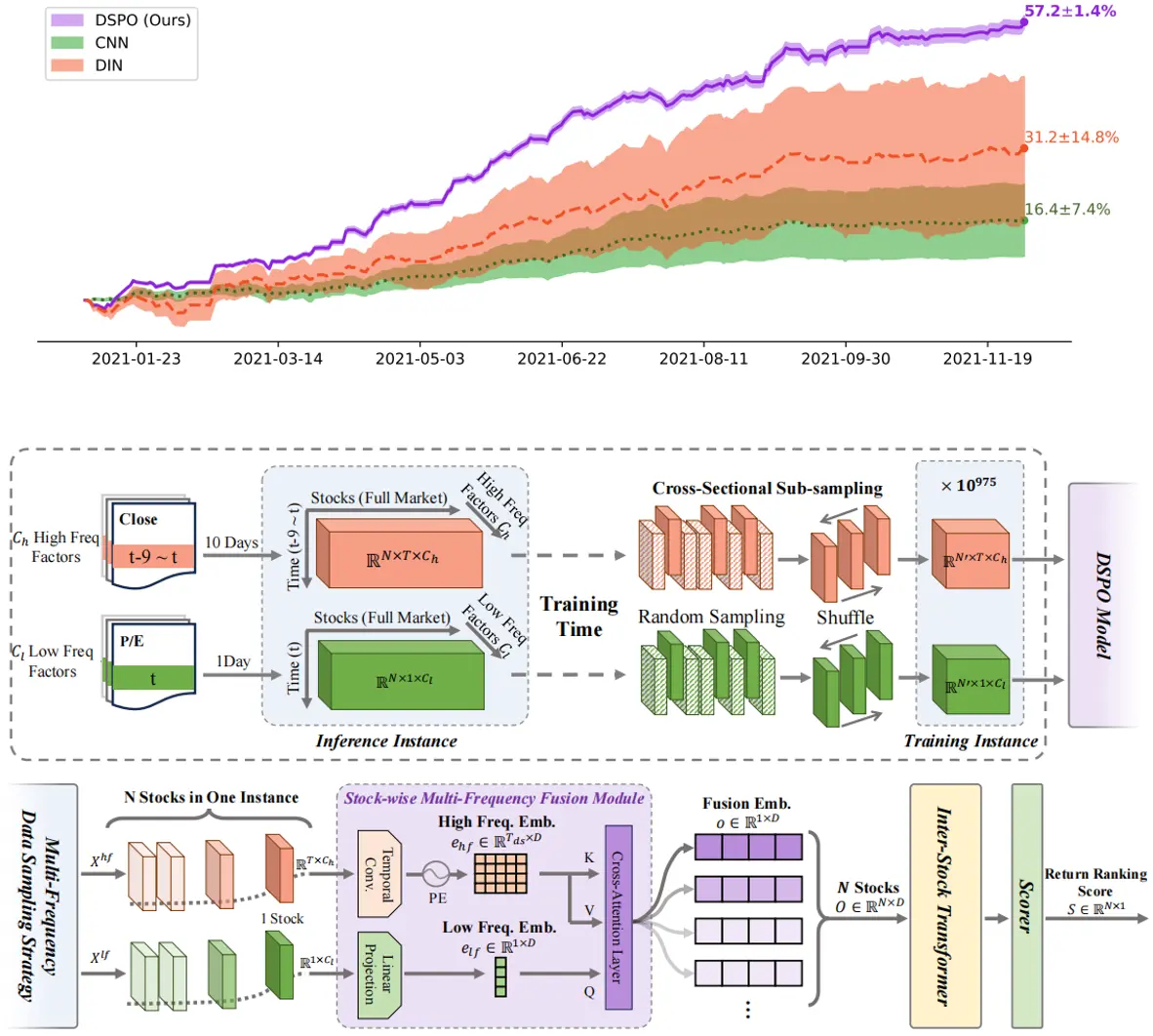
Jianyuan Zhong, Zhijian Xu, Saizhuo Wang, Xiangyu Wen, Jian Guo*, Qiang Xu*
DSPO: An End-to-End Framework for Direct Sorted Portfolio Construction.
https://arxiv.org/abs/2405.15833.
本文提出 DSPO,首个端到端框架直接从多频原始股票数据构建排序投资组合。亮点包括:1)CNN-Transformer融合高低频数据;2)Inter-Stock Transformer建模全市场股票关联;3)创新MonLR损失函数直接优化排序概率;4)子采样策略生成10^975量级训练样本。实验显示,DSPO在NYSE和A股市场RankIC达10.12%/9.11%,累计收益121.94%/108.74%,且方差仅为传统方法1/10,显著超越基准模型。
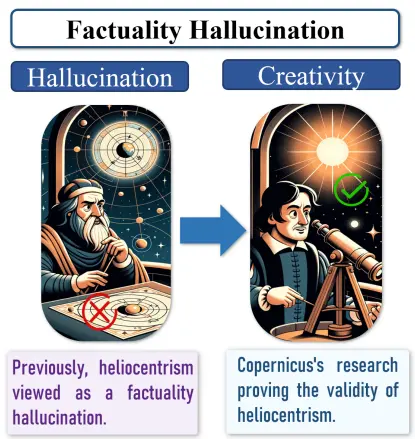
Xuhui Jiang, Yuxing Tian, Fengrui Hua, Chengjin Xu, Yuanzhuo Wang, Jian Guo* (2024)
A Survey on Large Language Model Hallucination via a Creativity Perspective.
https://arxiv.org/abs/2402.06647.
本文探讨了大语言模型(LLMs)幻觉与创造力的潜在关联,挑战了传统视幻觉为纯粹负面现象的观点。研究亮点包括:1)理论突破,提出幻觉可能是创造力的催化剂,类比科学史上"错误"推动创新的案例;2)方法论创新,基于认知科学的发散-收敛思维框架,系统梳理LLM幻觉转化机制;3)应用价值,通过多智能体交互和提示工程等策略,实现有害幻觉过滤与创意价值挖掘,为AI创造性应用开辟新范式。
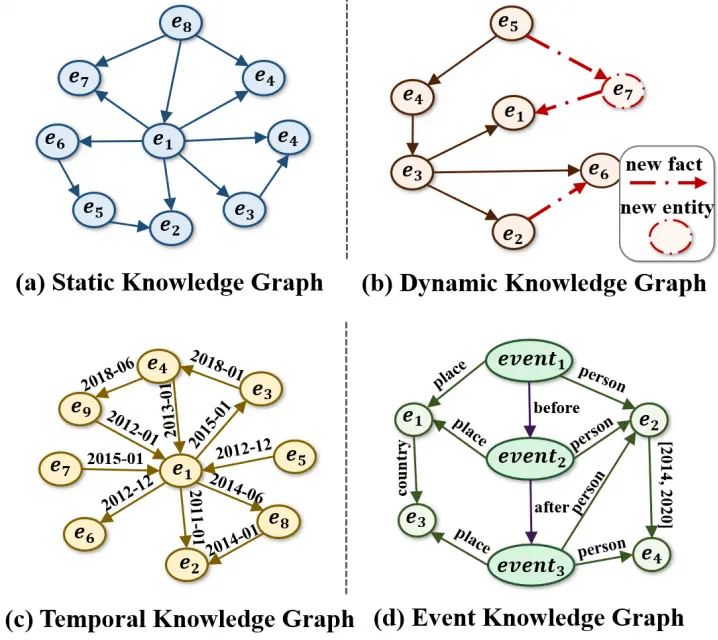
Xuhui Jiang, Chengjin Xu, Yinghan Shen, Xun Sun, Lumingyuan Tang, Saizhuo Wang, Zhongwu Chen, Yuanzhuo Wang, Jian Guo* (2023)
On the Evolution of Knowledge Graphs: A Survey and Perspective.
https://arxiv.org/abs/2310.04835.
本文系统综述了知识图谱(KGs)的演化历程与技术进展,核心亮点包括:1)提出四阶段演化框架(静态→动态→时序→事件KGs),定义各类图谱形式化表示;2)全面梳理知识抽取(如多模态事件抽取)与推理方法(矩阵分解/翻译/GNN/神经符号);3)创新性探讨KG与LLMs融合路径,揭示符号化与参数化知识表示的互补潜力;4)通过金融案例验证时序事件推理的实用价值,为量化投资等场景提供新范式。研究为动态知识工程与AI推理系统发展指明方向。
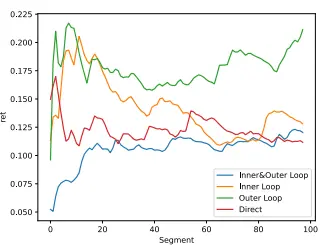
Saizhuo Wang, Hang Yuan, Lionel M. Ni, Jian Guo* (2023)
QuantAgent: Seeking Holy Grail in Trading by Self-Improving Large Language Model.
https://arxiv.org/abs/2402.03755.
本文提出QuantAgent——一种基于大语言模型(LLM)的自进化量化投资智能体,通过双层循环框架实现金融信号挖掘的自动化。核心亮点包括:1)内循环模拟推理环境,通过知识库迭代优化信号生成;2)外循环将信号投入真实市场验证并反哺知识库,形成闭环学习;3)理论证明该框架能以次线性计算成本收敛至最优策略。实验显示QuantAgent能持续提升信号质量(IC提升23%),在预测性能和交易理念贴合度上超越传统方法,为金融AI的自主进化提供了新范式。
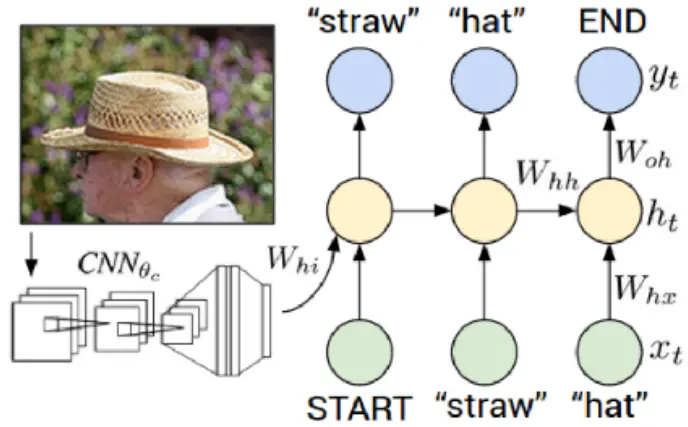
Zhengzhuo Xu, Sinan Du, Yiyan Qi, Chengjin Xu, Chun Yuan, Jian Guo* (2024)
ChartBench: A Benchmark for Complex Visual Reasoning in Charts.
https://arxiv.org/abs/2312.15915.
本文提出ChartBench——首个面向多模态大模型(MLLMs)的复杂图表推理评测基准,覆盖42类图表、66.6K样本及600K问答对,核心亮点包括:1)首创无标注图表评估框架,迫使模型通过颜色/坐标轴等视觉元素推理(85%测试数据无OCR依赖);2)设计Acc+评估指标,通过正负样本联合验证降低随机猜测率(较传统准确率提升评估鲁棒性);3)实验揭示主流MLLMs在未标注图表上平均性能下降34.4%(如GPT-4V从77.4%降至43%),暴露现有模型视觉逻辑缺陷。基准开源推动可信图表理解研究。
Feng Li, Hao Zhang, Yifan Zhang, Shilong Liu, Jian Guo, Lionel M. Ni, Pengchuan Zhang, Lei Zhang (2022)
Vision-Language Intelligence: Tasks, Representation Learning, and Large Models.
https://arxiv.org/abs/2203.01922.
本文系统综述了视觉-语言多模态智能(VL)的研究进展,将其划分为三大发展阶段:1)任务专用方法(2014-2018),针对图像描述、VQA等任务设计独立模型;2)预训练范式崛起(2019-2021),通过跨模态预训练(如ViLBERT、UNITER)学习语言对齐的视觉表征;3)大规模弱监督时代(2021至今),CLIP、DALL-E等利用海量网络数据实现零样本泛化。核心贡献在于提出VL研究的三大目标——对象级、语言对齐和语义丰富的视觉表征,并指出未来方向:模态协同、统一表征架构和知识增强。
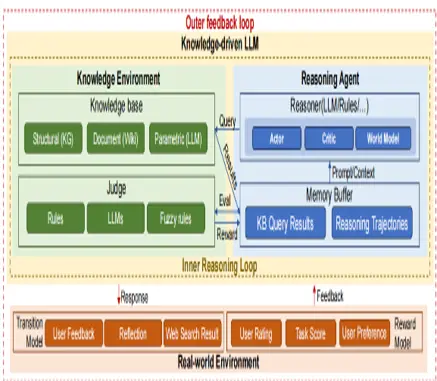
Saizhuo Wang, Zhihan Liu, Zhaoran Wang, Jian Guo* (2023)
A Principled Framework for Knowledge-enhanced Large Language Model.
https://arxiv.org/abs/2311.11135.
本文提出知识增强大语言模型(LLM)知识推理能力的闭环推理框架,建立LLM与知识图谱(KG)双层交互机制(内循环推理+外循环反馈),并建立数学理论框架。内循环将推理建模为马尔可夫决策过程(MDP),KG的知识实现贝叶斯决策的迭代推理,并从数学理论上证明其查询效率的数学遗憾边界为次线性(从数学理论上保证其计算的高效性);外循环引入用户反馈动态优化知识库,增强现实适应性。在KBQA任务中验证了知识锚定与可信推理的协同优势,为关键领域应用提供了数学理论保障。
Jian Guo*, Saizhuo Wang and Yiyan Qi (2024)
Guided Learning.
https://arxiv.org/abs/2411.10496.
本文提出Guided Learning(向导学习)框架,解决多阶段决策系统(如量化投资、自动驾驶)中端到端学习的崩溃与次优解问题。本文提出“向导guide”函数的目的:1)监督中间层训练,避免梯度崩溃,确保模型稳定性;2)结合奖励量化函数处理无监督决策场景,提升目标对齐能力和模型最终预测能力。向导学习可无缝集成监督、强化学习等经典范式,增强灵活性。在量化投资选股实验中优于传统阶段式方法(年化回报↑40%)及端到端基线方法(Sharpe比率↑12%),验证了向导学习的优势。
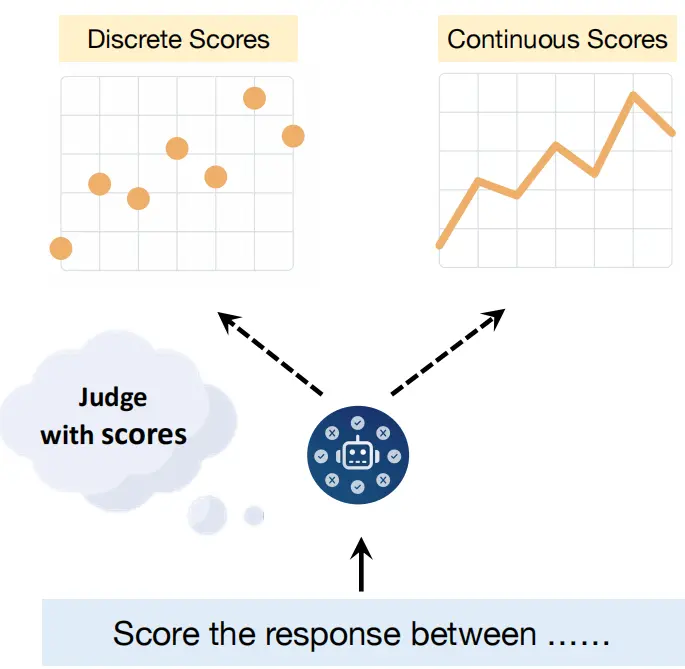
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Yuanzhuo Wang, Jian Guo* (2024)
A Survey on LLM-as-a-Judge.
https://arxiv.org/abs/2411.15594.
本文系统综述了LLM-as-a-Judge范式,提出其作为融合人类专家评估与自动指标优势的新型评估框架。核心亮点包括:1)形式化定义与四阶段分类(上下文学习/模型选择/后处理/评估流程);2)可靠性增强策略,涵盖提示设计优化、模型微调及结果校准;3)首创多维度元评估基准(CALM),量化12类偏差与对抗鲁棒性;4)揭示LLM评估与推理能力协同进化机制(如o1模型的自迭代优化)。实验显示GPT-4在金融/法律等场景评估一致性达61.54%,但存在位置/长度偏差等挑战。
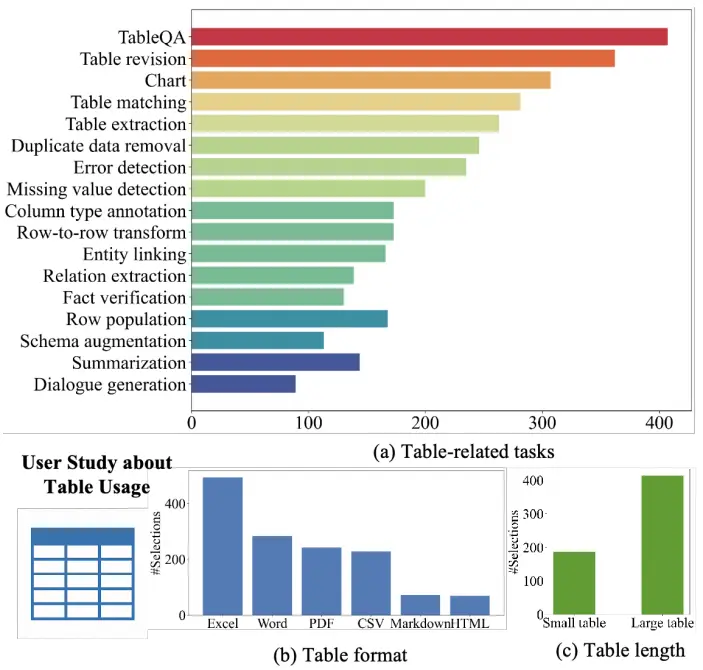
Jiasuho Sun, Chengjin Xu and Jian Guo* (2024)
TableLLM: Effective Training Framework for Table Reasoning in Large Language Models..
https://arxiv.org/abs/2403.19318v1.
本文提出TableLLM,一个专为真实办公场景设计的13B参数大语言模型,用于处理文档和电子表格中的表格数据操作。核心亮点包括:1)远程监督训练方法:通过扩展推理过程和跨方式验证策略提升数据质量;2)双场景支持:同时优化文档内表格(文本推理)和电子表格(代码驱动)任务;3)性能优势:在电子表格场景超越GPT-4(准确率90.7%),文档场景媲美GPT-3.5;4)实用部署:发布模型检查点、基准测试及网页应用,验证了在真实办公环境中的高效性。
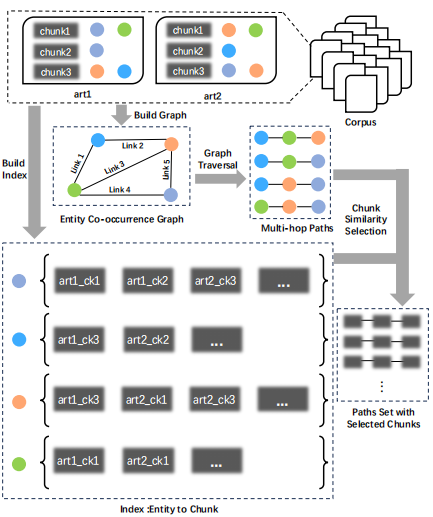
Xuhui Jiang, Shengjie Ma, Chengjin Xu, Cehao Yang, Liyu Zhang, Jian Guo* (2024)
Synthesis-on-Graph: Knowledgeable Synthetic Data Generation for Continues Pre-training of Large Language Models.
https://arxiv.org/abs/2505.00979.
本文提出Synthesize-on-Graph (SoG)框架,一种面向小规模专业语料的合成数据生成方法,通过跨文档知识关联显著提升LLM训练效率。其核心亮点在于:1)知识网络构建:基于实体提取与关联建立上下文图,突破传统单文档局限,实现多源信息融合;2)动态采样机制:结合广度优先搜索与语义相似度筛选,兼顾知识多样性、长尾覆盖与数据平衡性;3)混合生成策略:联合思维链推理与对比澄清技术,同步增强模型逻辑演绎与细粒度判别能力。实验验证其在多跳问答任务中性能超越现有方法: 1)性能提升:在MultiHop-RAG多跳问答任务中,SoG生成数据使Llama-3-8B模型准确率从55.3%提升至74.1%(4.5倍数据量时),较基线方法EntiGraph提升3.2个百分点;2)长尾覆盖:通过对比澄清(CC)策略,将原始语料中低频实体的覆盖率从不足20%提升至95%以上,显著改善知识不平衡问题;3)训练效率:仅需1.5倍原始数据量即可达到70.9%准确率,验证其数据高效性;4)泛化能力:在QUALITY阅读理解任务中保持47.5%准确率,与SOTA方法相当,展现跨任务适应性。该框架为数据稀缺场景下的LLM持续预训练提供了兼具性能与效率的解决方案。
Cehao Yang, Xueyuan Lin, Chengjin Xu, Xuhui Jiang, Xiaojun Wu, Honghao Liu, Hui Xiong, Jian Guo* (2025)
Select2Reason: Efficient Instruction-Tuning Data Selection for Long-CoT Reasoning.
https://arxiv.org/abs/2505.17266.
SELECT2REASON提出了一种针对长思维链推理的高效指令选择框架,通过联合优化问题难度(采用微调的LLM-as-Judge量化评估)与推理轨迹长度(实证显示长轨迹包含更高频率的反思行为词如"Wait/Alternatively"),设计动态平衡两者的联合排序器;实验表明仅选择10%数据微调的模型在9项数学基准中超越全量训练效果,推理效率提升30%,并能零成本迁移至中文指令池,为激活大模型复杂推理能力提供了高效新范式。
技术发明专利(Patents)

- 郭健、郭家栋。(2019)一种数据处理框架、方法及系统。专利号:ZL201911145908.0。
- 赵恺、郭健、郭家栋。(2019)一种预测结果生成方法、终端及存储介质。专利号:ZL201911142180.6
- 付维麟、况琨、郭健。(2020)一种目标变量预测模型的生成方法、系统及装置。专利号:ZL202010750071.9。
- 齐逸岩、张皓涵、徐铖晋、林舟驰、郭健。(2024)图表分析方法、装置、设备及存储介质。专利号:ZL202410181848.2。证书号第7093620号。
- 齐逸岩、苏嘉俊、林舟驰、郭健。(2024)基于大语言模型的多轮问答方法、系统、终端及存储介质。专利号:ZL202410179941.X。证书号第7060810号。
- 苏嘉俊、林舟驰、王馥玮、齐逸岩、郭健。(2024)基于文本内容的问题生成方法、系统及相关设备。专利号:ZL202410806172.1。证书号第7451680号。
- 苏嘉俊、林舟驰、王馥玮、齐逸岩、郭健。(2024)基于文本的内容推荐方法、系统、智能终端及介质。专利号:ZL202410791098.0。证书号第7424436号。
- 苏嘉俊、王馥玮、林舟驰、郭健。(2024)一种用户提问的处理方法、装置、设备及存储介质。专利号:ZL202430476002.2。证书号第9277138号。
- 齐逸岩、田宇星、幺宝刚、郭健。(2024)节点交互的预测方法、模型、终端及介质。专利号:ZL202410238511.0。证书号第7087406号。
- 齐逸岩、田宇星、幺宝刚、郭健。(2024)连续时间动态图模型的构建方法、装置、设备及存储介质。专利号:ZL202411118731.6。证书号第7633577号。
- 江旭晖、徐铖晋、杨策皓、林舟驰、郭健。(2025)基于语言模型的训练语料生成方法、系统、终端及介质。专利号:ZL202510129515.X。证书号第7899610号。
软件著作权(Software Copyrights)

- IDEA金融程序化算法交易平台。(2022)软件登记号:2022SR0430600。软著登字第9384799号。
- IdeaQuant雪球看看软件。(2024)软件登记号:2024SR0302112。软著登字第12705985号。
- ideaQuant下一代AI投资研究系统。(2024)软件登记号:2024SR0408818。软著登字第12812691号。
- IDEA大规模分布式金融信号挖掘系统。(2024)软件登记号:2024SR0406409。软著登字第12810282号。
- Alpha-GPT交互式金融信号研发平台。(2024)软件登记号:2024SR0406396。软著登字第12810269号。
- ideaQuant上市公司风险动态预测系统。(2024)软件登记号:2024SR0408882。软著登字第12812755号。
- 基于大数据的金融信号计算平台。(2024)软件登记号:2024SR0420499。软著登字第12824372号。
- ideaQuant 场内期权离线定价系统。(2024)软件登记号:2022SR0430600。软著登字第9384799号。
- IDEA经济超脑客户端软件。(2024)软件登记号:2024SR1220604。软著登字第13624477号。
- ideaQuant金融行为知识管理系统。(2024)软件登记号:2024SR0420496。软著登字第12824369号。
- ideaQuant行业阿尔法预测系统。(2024)软件登记号:2024SR0420495。软著登字第12824368号。