


大模型“一本正经地胡说八道”的幻觉(Hallucination)问题,一直是制约其广泛应用的瓶颈。由碎片化语料训练而来的大模型,不仅在深度推理方面表现不佳,也存在推理过程不透明、难以自我纠错的短板。
近日,粤港澳大湾区数字经济研究院(简称“IDEA 研究院”)人工智能金融与深度学习研究中心研发 Think-on-Graph(思维图谱)技术,让大模型(LLM)与知识谱图(KG)的紧耦合交互,驱动 LLM 智能体在 KG 的关联实体上一步一步搜索推理出最优答案。
实验结果表明,Think-on-Graph 在深度推理问题上的表现较 ChatGPT 最多可提升 253%,并将知识推理过程透明化,实现知识的可追溯、可纠错与可修正。与此同时,Think-on-Graph 还具备免训练即插即用、低算力消耗、实时知识更新等特性,在众多实际场景中有广泛的应用潜力。
我们先通过一个案例,来认识 Think-on-Graph 的不同之处。
问:“金庸小说中段誉和洪七公谁的武功更高”?
段誉和洪七公分别为《天龙八部》与《射雕英雄传》的重要角色,但两者从未在同一部作品中出现。这类“关公战秦琼”的提问,对 LLM 来说挑战不小。
以下是 GPT-4 的回答:
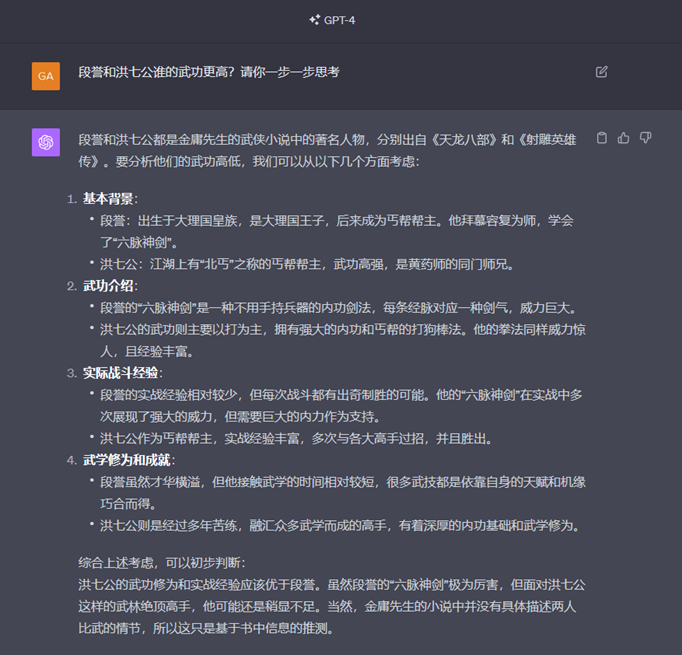
不难看出,经碎片化语料训练而出的 LLM 难以胜任“线索分析”型的深度推理问题:
► 首先,幻觉现象依旧明显,比如回答中“段誉……拜慕容复为师,学会六脉神剑”、”洪七公……是黄药师的同门师兄”在小说中未曾出现。
►此外,GPT-4 对两位人物武功水平的比较也缺少深度逻辑分析,更多是罗列表象事实,如“段誉……接触武学的时间相对较短”和“洪七公则是经过多年苦练”,并不能直接推出“洪七公的武功修为……应该优于段誉”这个结论。
接下来,我们看看 Think-on-Graph 的答题思路:
Think-on-Graph 的回答不仅逻辑条理清晰,更可追溯出逻辑推理链条,这正得益于 LLM 推理能力与 KG 结构化知识的深度融合:
► 根据 KG 中“六脉神剑是大理段氏最强武功”而“一阳指是大理段氏常用武功”的信息,LLM 可以推理出“六脉神剑”强于“一阳指”,从而推理出段誉的武功强于一灯大师;
► 继而又根据 KG 上的“一灯大师和洪七公同属‘华山四绝’”,推理出两人武功相当,最后得出段誉的武功高于洪七公的结论。
紧耦合 LLM 与 KG 实现深度推理
如上文所述,Think-on-Graph 融合了大模型和知识图谱的优势,从而实现能力的质的提升。

总的来说,LLM 更擅长推理、意图理解、内容生成和学习,而 KG 因其结构化的知识存储方式,更擅长逻辑链条推理并具有更好的推理透明度和可信度,可见他们之间互补性很强。
如果用适当的方法融合 LLM 与 KG 的优点,取长补短,KG 就有机会帮助提升 LLM 的推理能力和知识水平。反过来,大模型的推理能力也可以帮助 KG 的构建、完善、纠错和质量控制,提升知识图谱的准确度、覆盖度和完备度。
事实上,通过 LLM 与 KG 的融合来弥补 LLM 能力短板,是近期的研究热点之一。当下主流方法分为两类。
第一类方法是在模型预训练阶段融合二者。这类方法又细分为:1.在 LLM 模型输入层融合,利用 KG 扩充输入层特征;2.在 LLM 模型网络层融合,利用图表示等技术将 KG 嵌入到 LLM 网络架构中;3.在 LLM 模型输出层融合,利用 KG 来约束模型训练任务。此类方法在知识层面融合了 LLM 与 KG,但需要额外的训练时间,且牺牲掉 KG 的实时知识更新能力与可解释性等天然优势。
第二种方法则是利用 KG 的知识结构,通过适当的自动化提示工程(prompt engineering)来实现融合。这其中又分为两种范式:松耦合范式和紧耦合范式。本文提出的 Think-on-Graph 算法就属于后者,通过将 LLM 与 KG 的优势深度融合,实现推理能力的突破。
松耦合范式
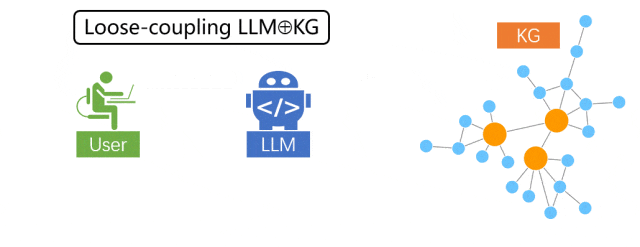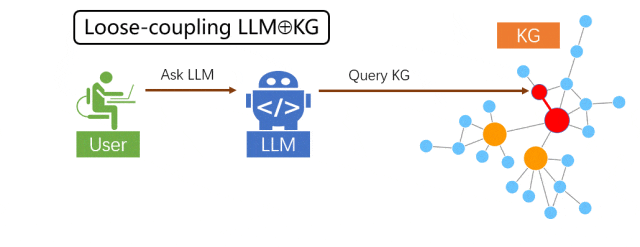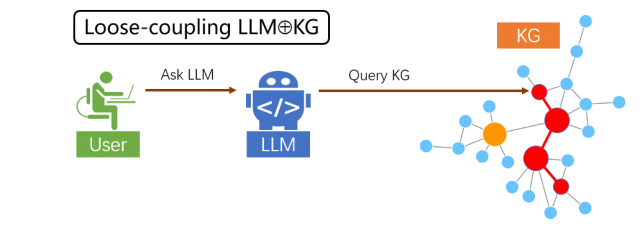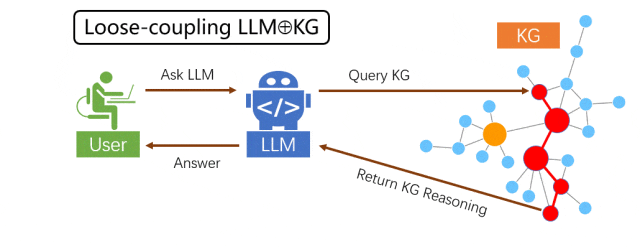
在松耦合范式中,大模型的角色为“翻译官”,试图理解用户输入的自然语言背后的意图,并 “翻译”成 KG 查询语言,再将 KG 上的搜索结果反向“翻译”给用户,可以看成一种特殊的大模型信息检索增强。此范式存在的局限性是,它严重依赖 KG 本身的信息质量和完整度,在 KG 信息缺失的情况下,无法直接借助 LLM 的内在知识和推理能力来补齐。
紧耦合范式
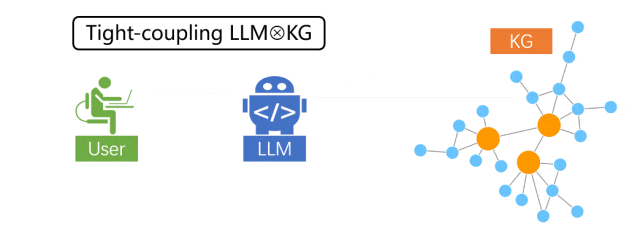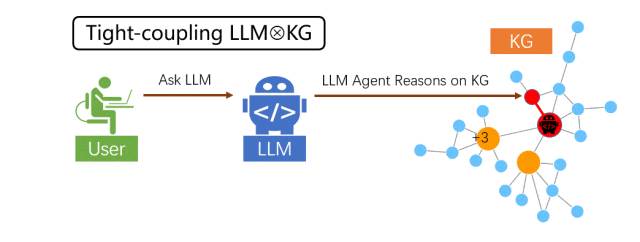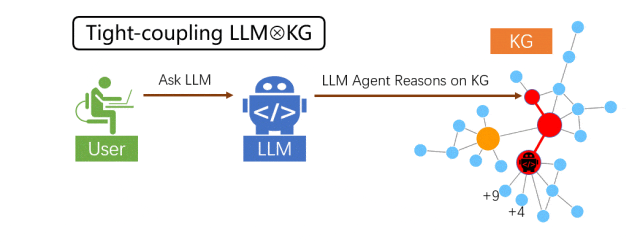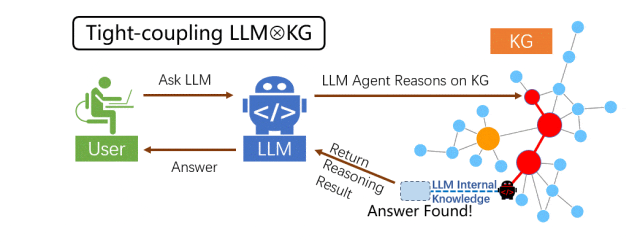
在紧耦合中,大模型充当 Agent(智能体)“跑腿”角色,在 KG 的实体结点上一步一步地搜索与推理,直到推出最终答案。在此范式下,大模型亲自参与到 KG 的每一步推理中,与 KG 紧密互动,信息互补,从而提升整体的推理能力。
以下,我们用一个例子来解释紧耦合范式的优势。
问:“堪培拉所在国家当前的多数党是哪个党派”?
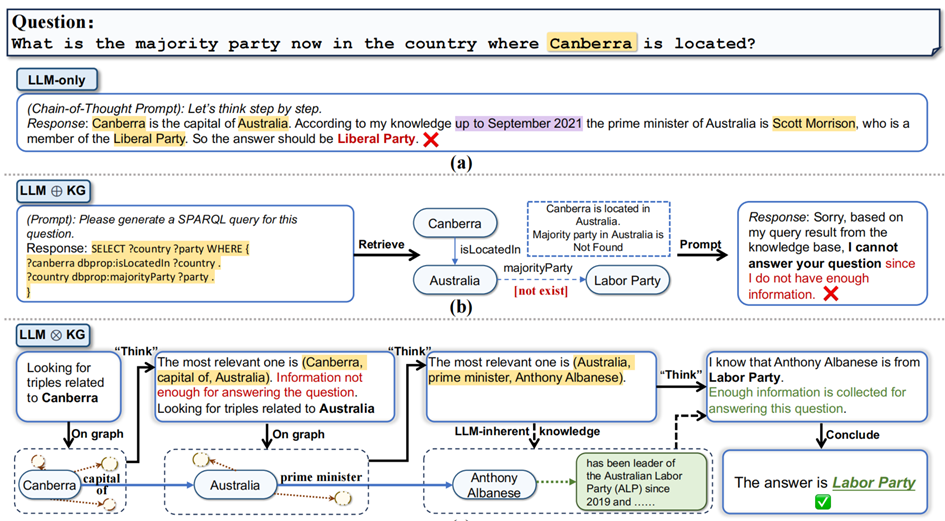
► ChatGPT 由于信息只更新至 2021 年,生成错误答案“自由党”。
► 松耦合范式虽然引入了具有最新信息的知识图谱,但由于其中缺少了“多数党”这一信息,导致推理卡在中间步骤,无法完成。
► 紧耦合范式中,大模型通过猜测“议会制国家的政府首脑(总理)通常也是多数党领袖”,弥补了知识图谱在“多数党”信息上的缺失,从而绕道推理出正确答案。
Think-on-Graph,
高效实现紧耦合
紧耦合范式提供了一种让 LLM 与 KG 联合建模的范式。就具体算法而言,Think-on-Graph 借鉴了 Transformer 在自然语言推理中常用的 beam-search 算法思路,实现高效搜索和推理。该算法本身是一个迭代过程,在每次循环内,要先后完成两个任务:搜索剪枝与推理决策。
搜索剪枝的目的是找出最有希望成为正确答案的推理路径—— 以当前 KG 实体为中心,去遍历搜索与其相邻的每一个实体,再用 LLM 计算出相对打分(分值高低代表此新实体加入已有推理路径后,可以正确回答原问题的能力),并将得分最高的 N 个(N=搜索宽度) “邻居”实体所引出的 N 条候选推理路径保留下来。
推理决策任务则用 LLM 来判断已有的候选推理路径是否足以回答问题,如果判断为否,则继续迭代到下一次循环,直到找出满意答案。
我们依然借用上述例子来解释 Think-on-Graph 算法的思路。
问:“堪培拉所在国家当前的多数党是哪个党派”?

上图演示了用搜索宽度 N=2 的 beam-search 来实现 Think-on-Graph 推理。在搜索剪枝任务中,LLM 从关键词 Canberra 出发,匹配到 KG 中最接近(或一致)的实体 Canberra。
此后流程如动图所示,LLM 从实体 Canberra 出发,分别搜索了 5 个“关系 → 实体”对,并对其分别打分:continent → Australian continent 获得 3 分, part of → Canberra-Queanbeyan 获得 2 分,official-language → English 获得 1 分,capital of → Australia 获得 8 分,located in → Australian Capital Territory 获得 7 分。
对 5 组“关系 → 实体”对的得分进行从高到低排序后,LLM 选取得分最高的 2 个保留下来,形成了两条候选推理路径:
1. Canberra – located in → Australian Capital Territory
2. Canberra – capital of → Australia
在推理决策任务中,LLM 对以上两条候选推理路径进行评估,通过 Yes/No 回答,反馈 Think-on-Graph 算法是否已找到满意的答案并结束迭代。显然,在这个例子中,LLM 的判断是“否”,因此进入第二轮迭代,分别以实体 Australian Capital Territory 和实体 Australia 为中心,来搜索其周边相邻的实体,再次选取出两条得分最高的候选路径:
1. Canberra – capital of → Australia – head of government → Anthony Albanese
2. Canberra – capital of → Australia – office held by head of government → Prime Minister of Australia
第二轮推理决策中,上述两条路径再次被 LLM 否决,因此开启第三轮迭代,得分最高的两条推理路径如下:
1. Canberra – capital of → Australia – head of government → Anthony Albanese – member of → Labor Party
2. Canberra – capital of → Australia – head of government → Anthony Albanese – Politician
这一次,LLM 经过认为当前已经获取足够的信息来回答问题,于是停止了算法迭代,将包含 Labor Party(工党)的答案输出给用户。
让推理可解释,
让知识可追溯,让错误可修正
在金融、制造业、物流、医疗、法律、公共服务等容错率极低的严肃领域,精度和准确度的重要性不言自明。因此,大模型推理的可信度、透明度与修正能力,对其在此类场景的可落地性至关重要。
Think-on-Graph 的另一主要优势,是实现了大模型的“推理可解释、知识可追溯、错误可修正”,特别是借助人工反馈和 LLM 的推理能力,发现并修正 KG 上的错误信息。
为便于理解,我们设计一个实验:在前述“段誉 vs.洪七公”案例的 KG 中,故意掺入错误信息“大理段氏的最强武功是一阳指,一般武功是六脉神剑”(事实正相反),来观察推理结果有何变化。

由于 KG 的错误知识,Think-on-Graph 推理出错误的答案“洪七公的武功高于段誉”。然而,由于 Think-on-Graph 中内置了“自我反思”能力,即当判断输出答案的可信度不足时,会自动回溯 KG 上的推理路径,检查路径中的每一个三元组,并通过 LLM 自有的知识将 KG 上内容“可疑”的三元组挑选出来,向用户反馈可疑信息的分析和纠错建议,由用户决定是否纠正。在本例中,Think-on-Graph 在检测到答案可信度不高后,自动进行了“自我反思”并提供了纠错建议。

根据用户的要求,Think-on-Graph 可以修正可疑三元组,并再次推理出新的答案。
在多个问答数据集上
取得 SOTA,表现超越 ChatGPT
研究团队在四类知识密集型任务(KBQA, Open-Domain QA, Slot Filling, Fact Checking)共 9 个数据集上对 ToG 算法进行了评估,以评价其推理准确度。
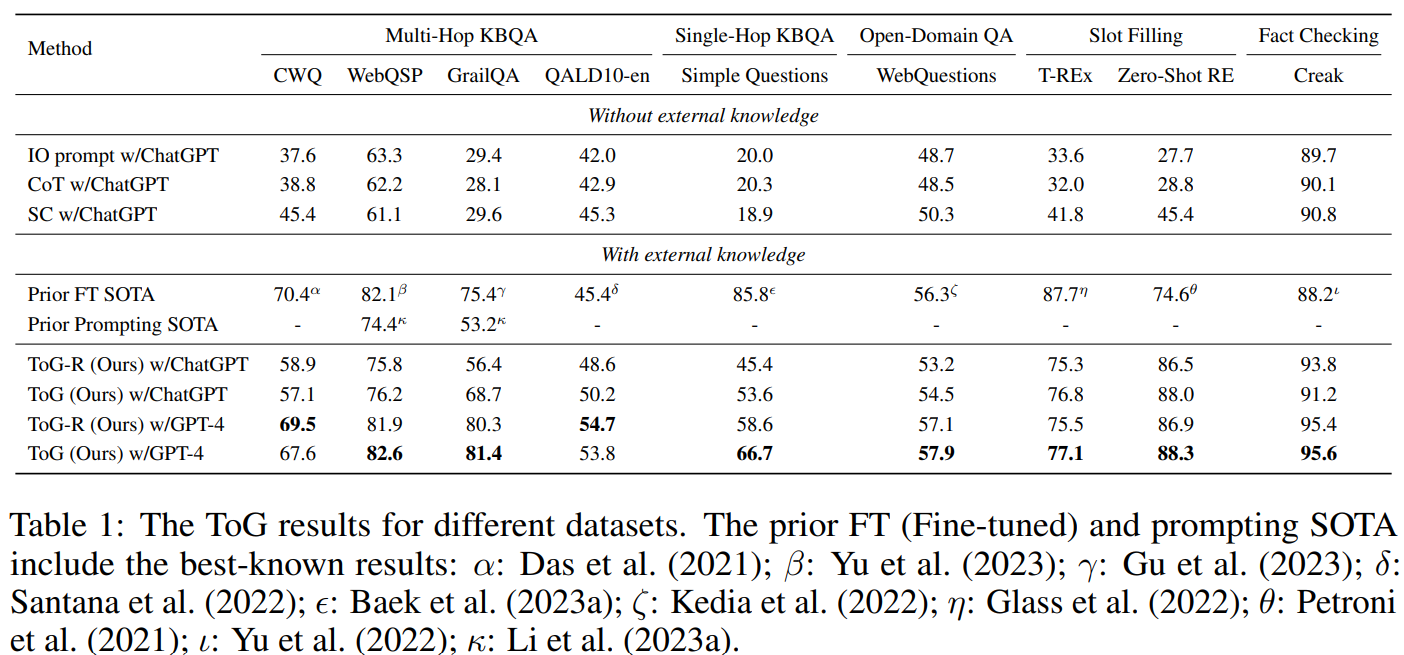
从结果可见,在所有数据集上,Think-on-Graph 相较于不同 prompting 策略(IO, CoT 以及 CoT-SC)下的 ChatGPT 均有显著提升。例如,在 Zeroshot-RE 数据集上,基于 CoT 的 ChatGPT 精度为 28.8%,而同样以 ChatGPT 作为底座 LLM 的 Think-on-Graph 精度达到 88%。
团队发现,当 Think-on-Graph 的底座模型从 ChatGPT(GPT-3.5)升级为 GPT-4 后,其推理精度进一步提升,在 6 个数据集上取得了 SOTA,其余 3 个数据集中的 CWQ 上十分接近 SOTA。
由于 Think-on-Graph 完全没有在任何一个测试数据集上进行过监督学习性质的增量训练或增量微调,上述结果反映了 Think-on-Graph 即插即用的优势。
此外,研究还发现,即便将 Think-on-Graph 的底座模型替换成小规模 LLM(如 LLAMA2-70B),依然可在多个数据集上超过 ChatGPT 本身的表现,这为大模型使用者提供了一条低成本、低算力的可行技术路线。
Think-on-Graph 优势总结
深度推理:发挥 KG 结构化知识在逻辑推理上天然的优势,增强 LLM 在知识深度推理任务上的能力。
可信推理:充分发挥知识图谱数据结构化的优势,借助大模型的推理能力实现知识可追溯和知识可纠错。
知识实时性:KG 的知识可以更快的更新,可弥补 LLM 训练时间长、知识更新慢的缺点。
低算力消耗:小规模 LLM 融合知识图谱可以在很多场景下取得比大规模 LLM 更好的表现,可显著降低算力成本、部署成本和时间成本。
即插即用:可根据具体场景和需求灵活对接和更换不同的 LLM 与 KG,无额外训练成本。
研究团队介绍
Think-on-Graph 的工作主要在 IDEA 研究院人工智能金融与深度学习研究中心(IDEA FinAI)完成。IDEA FinAI 的目标是研发世界前沿的 AI 技术让金融更精准、更迅捷、更安全,核心研究项目包括:Quant4.0 下一代 AI 量化投资技术、知识驱动大模型技术、金融行为知识图谱技术等,及其应用产业落地与商业化。
论文有四名共同第一作者:IDEA 研究院资深研究员徐铖晋博士,研究实习生孙嘉硕、汤陆明远和王赛卓。论文通讯作者为 IDEA 研究院郭健博士。除 IDEA 之外,本论文参与方还包括微软亚洲研究院、香港科技大学、香港科技大学(广州)、厦门大学和美国南加州大学。
如想了解 IDEA-HKUST(GZ)联合博士培养项目,请点击。此项目面向全球招生,研究方向聚焦人工智能与数字经济前沿科技。
大模型“一本正经地胡说八道”的幻觉(Hallucination)问题,一直是制约其广泛应用的瓶颈。由碎片化语料训练而来的大模型,不仅在深度推理方面表现不佳,也存在推理过程不透明、难以自我纠错的短板。
近日,粤港澳大湾区数字经济研究院(简称“IDEA 研究院”)人工智能金融与深度学习研究中心研发 Think-on-Graph(思维图谱)技术,让大模型(LLM)与知识谱图(KG)的紧耦合交互,驱动 LLM 智能体在 KG 的关联实体上一步一步搜索推理出最优答案。
实验结果表明,Think-on-Graph 在深度推理问题上的表现较 ChatGPT 最多可提升 253%,并将知识推理过程透明化,实现知识的可追溯、可纠错与可修正。与此同时,Think-on-Graph 还具备免训练即插即用、低算力消耗、实时知识更新等特性,在众多实际场景中有广泛的应用潜力。
我们先通过一个案例,来认识 Think-on-Graph 的不同之处。
问:“金庸小说中段誉和洪七公谁的武功更高”?
段誉和洪七公分别为《天龙八部》与《射雕英雄传》的重要角色,但两者从未在同一部作品中出现。这类“关公战秦琼”的提问,对 LLM 来说挑战不小。
以下是 GPT-4 的回答:
不难看出,经碎片化语料训练而出的 LLM 难以胜任“线索分析”型的深度推理问题:
► 首先,幻觉现象依旧明显,比如回答中“段誉……拜慕容复为师,学会六脉神剑”、”洪七公……是黄药师的同门师兄”在小说中未曾出现。
►此外,GPT-4 对两位人物武功水平的比较也缺少深度逻辑分析,更多是罗列表象事实,如“段誉……接触武学的时间相对较短”和“洪七公则是经过多年苦练”,并不能直接推出“洪七公的武功修为……应该优于段誉”这个结论。
接下来,我们看看 Think-on-Graph 的答题思路:
Think-on-Graph 的回答不仅逻辑条理清晰,更可追溯出逻辑推理链条,这正得益于 LLM 推理能力与 KG 结构化知识的深度融合:
► 根据 KG 中“六脉神剑是大理段氏最强武功”而“一阳指是大理段氏常用武功”的信息,LLM 可以推理出“六脉神剑”强于“一阳指”,从而推理出段誉的武功强于一灯大师;
► 继而又根据 KG 上的“一灯大师和洪七公同属‘华山四绝’”,推理出两人武功相当,最后得出段誉的武功高于洪七公的结论。
紧耦合 LLM 与 KG 实现深度推理
如上文所述,Think-on-Graph 融合了大模型和知识图谱的优势,从而实现能力的质的提升。
总的来说,LLM 更擅长推理、意图理解、内容生成和学习,而 KG 因其结构化的知识存储方式,更擅长逻辑链条推理并具有更好的推理透明度和可信度,可见他们之间互补性很强。
如果用适当的方法融合 LLM 与 KG 的优点,取长补短,KG 就有机会帮助提升 LLM 的推理能力和知识水平。反过来,大模型的推理能力也可以帮助 KG 的构建、完善、纠错和质量控制,提升知识图谱的准确度、覆盖度和完备度。
事实上,通过 LLM 与 KG 的融合来弥补 LLM 能力短板,是近期的研究热点之一。当下主流方法分为两类。
第一类方法是在模型预训练阶段融合二者。这类方法又细分为:1.在 LLM 模型输入层融合,利用 KG 扩充输入层特征;2.在 LLM 模型网络层融合,利用图表示等技术将 KG 嵌入到 LLM 网络架构中;3.在 LLM 模型输出层融合,利用 KG 来约束模型训练任务。此类方法在知识层面融合了 LLM 与 KG,但需要额外的训练时间,且牺牲掉 KG 的实时知识更新能力与可解释性等天然优势。
第二种方法则是利用 KG 的知识结构,通过适当的自动化提示工程(prompt engineering)来实现融合。这其中又分为两种范式:松耦合范式和紧耦合范式。本文提出的 Think-on-Graph 算法就属于后者,通过将 LLM 与 KG 的优势深度融合,实现推理能力的突破。
松耦合范式
在松耦合范式中,大模型的角色为“翻译官”,试图理解用户输入的自然语言背后的意图,并 “翻译”成 KG 查询语言,再将 KG 上的搜索结果反向“翻译”给用户,可以看成一种特殊的大模型信息检索增强。此范式存在的局限性是,它严重依赖 KG 本身的信息质量和完整度,在 KG 信息缺失的情况下,无法直接借助 LLM 的内在知识和推理能力来补齐。
紧耦合范式
在紧耦合中,大模型充当 Agent(智能体)“跑腿”角色,在 KG 的实体结点上一步一步地搜索与推理,直到推出最终答案。在此范式下,大模型亲自参与到 KG 的每一步推理中,与 KG 紧密互动,信息互补,从而提升整体的推理能力。
以下,我们用一个例子来解释紧耦合范式的优势。
问:“堪培拉所在国家当前的多数党是哪个党派”?
► ChatGPT 由于信息只更新至 2021 年,生成错误答案“自由党”。
► 松耦合范式虽然引入了具有最新信息的知识图谱,但由于其中缺少了“多数党”这一信息,导致推理卡在中间步骤,无法完成。
► 紧耦合范式中,大模型通过猜测“议会制国家的政府首脑(总理)通常也是多数党领袖”,弥补了知识图谱在“多数党”信息上的缺失,从而绕道推理出正确答案。
Think-on-Graph,
高效实现紧耦合
紧耦合范式提供了一种让 LLM 与 KG 联合建模的范式。就具体算法而言,Think-on-Graph 借鉴了 Transformer 在自然语言推理中常用的 beam-search 算法思路,实现高效搜索和推理。该算法本身是一个迭代过程,在每次循环内,要先后完成两个任务:搜索剪枝与推理决策。
搜索剪枝的目的是找出最有希望成为正确答案的推理路径—— 以当前 KG 实体为中心,去遍历搜索与其相邻的每一个实体,再用 LLM 计算出相对打分(分值高低代表此新实体加入已有推理路径后,可以正确回答原问题的能力),并将得分最高的 N 个(N=搜索宽度) “邻居”实体所引出的 N 条候选推理路径保留下来。
推理决策任务则用 LLM 来判断已有的候选推理路径是否足以回答问题,如果判断为否,则继续迭代到下一次循环,直到找出满意答案。
我们依然借用上述例子来解释 Think-on-Graph 算法的思路。
问:“堪培拉所在国家当前的多数党是哪个党派”?
上图演示了用搜索宽度 N=2 的 beam-search 来实现 Think-on-Graph 推理。在搜索剪枝任务中,LLM 从关键词 Canberra 出发,匹配到 KG 中最接近(或一致)的实体 Canberra。
此后流程如动图所示,LLM 从实体 Canberra 出发,分别搜索了 5 个“关系 → 实体”对,并对其分别打分:continent → Australian continent 获得 3 分, part of → Canberra-Queanbeyan 获得 2 分,official-language → English 获得 1 分,capital of → Australia 获得 8 分,located in → Australian Capital Territory 获得 7 分。
对 5 组“关系 → 实体”对的得分进行从高到低排序后,LLM 选取得分最高的 2 个保留下来,形成了两条候选推理路径:
1. Canberra – located in → Australian Capital Territory
2. Canberra – capital of → Australia
在推理决策任务中,LLM 对以上两条候选推理路径进行评估,通过 Yes/No 回答,反馈 Think-on-Graph 算法是否已找到满意的答案并结束迭代。显然,在这个例子中,LLM 的判断是“否”,因此进入第二轮迭代,分别以实体 Australian Capital Territory 和实体 Australia 为中心,来搜索其周边相邻的实体,再次选取出两条得分最高的候选路径:
1. Canberra – capital of → Australia – head of government → Anthony Albanese
2. Canberra – capital of → Australia – office held by head of government → Prime Minister of Australia
第二轮推理决策中,上述两条路径再次被 LLM 否决,因此开启第三轮迭代,得分最高的两条推理路径如下:
1. Canberra – capital of → Australia – head of government → Anthony Albanese – member of → Labor Party
2. Canberra – capital of → Australia – head of government → Anthony Albanese – Politician
这一次,LLM 经过认为当前已经获取足够的信息来回答问题,于是停止了算法迭代,将包含 Labor Party(工党)的答案输出给用户。
让推理可解释,
让知识可追溯,让错误可修正
在金融、制造业、物流、医疗、法律、公共服务等容错率极低的严肃领域,精度和准确度的重要性不言自明。因此,大模型推理的可信度、透明度与修正能力,对其在此类场景的可落地性至关重要。
Think-on-Graph 的另一主要优势,是实现了大模型的“推理可解释、知识可追溯、错误可修正”,特别是借助人工反馈和 LLM 的推理能力,发现并修正 KG 上的错误信息。
为便于理解,我们设计一个实验:在前述“段誉 vs.洪七公”案例的 KG 中,故意掺入错误信息“大理段氏的最强武功是一阳指,一般武功是六脉神剑”(事实正相反),来观察推理结果有何变化。
由于 KG 的错误知识,Think-on-Graph 推理出错误的答案“洪七公的武功高于段誉”。然而,由于 Think-on-Graph 中内置了“自我反思”能力,即当判断输出答案的可信度不足时,会自动回溯 KG 上的推理路径,检查路径中的每一个三元组,并通过 LLM 自有的知识将 KG 上内容“可疑”的三元组挑选出来,向用户反馈可疑信息的分析和纠错建议,由用户决定是否纠正。在本例中,Think-on-Graph 在检测到答案可信度不高后,自动进行了“自我反思”并提供了纠错建议。
根据用户的要求,Think-on-Graph 可以修正可疑三元组,并再次推理出新的答案。
在多个问答数据集上
取得 SOTA,表现超越 ChatGPT
研究团队在四类知识密集型任务(KBQA, Open-Domain QA, Slot Filling, Fact Checking)共 9 个数据集上对 ToG 算法进行了评估,以评价其推理准确度。
从结果可见,在所有数据集上,Think-on-Graph 相较于不同 prompting 策略(IO, CoT 以及 CoT-SC)下的 ChatGPT 均有显著提升。例如,在 Zeroshot-RE 数据集上,基于 CoT 的 ChatGPT 精度为 28.8%,而同样以 ChatGPT 作为底座 LLM 的 Think-on-Graph 精度达到 88%。
团队发现,当 Think-on-Graph 的底座模型从 ChatGPT(GPT-3.5)升级为 GPT-4 后,其推理精度进一步提升,在 6 个数据集上取得了 SOTA,其余 3 个数据集中的 CWQ 上十分接近 SOTA。
由于 Think-on-Graph 完全没有在任何一个测试数据集上进行过监督学习性质的增量训练或增量微调,上述结果反映了 Think-on-Graph 即插即用的优势。
此外,研究还发现,即便将 Think-on-Graph 的底座模型替换成小规模 LLM(如 LLAMA2-70B),依然可在多个数据集上超过 ChatGPT 本身的表现,这为大模型使用者提供了一条低成本、低算力的可行技术路线。
Think-on-Graph 优势总结
深度推理:发挥 KG 结构化知识在逻辑推理上天然的优势,增强 LLM 在知识深度推理任务上的能力。
可信推理:充分发挥知识图谱数据结构化的优势,借助大模型的推理能力实现知识可追溯和知识可纠错。
知识实时性:KG 的知识可以更快的更新,可弥补 LLM 训练时间长、知识更新慢的缺点。
低算力消耗:小规模 LLM 融合知识图谱可以在很多场景下取得比大规模 LLM 更好的表现,可显著降低算力成本、部署成本和时间成本。
即插即用:可根据具体场景和需求灵活对接和更换不同的 LLM 与 KG,无额外训练成本。
研究团队介绍
Think-on-Graph 的工作主要在 IDEA 研究院人工智能金融与深度学习研究中心(IDEA FinAI)完成。IDEA FinAI 的目标是研发世界前沿的 AI 技术让金融更精准、更迅捷、更安全,核心研究项目包括:Quant4.0 下一代 AI 量化投资技术、知识驱动大模型技术、金融行为知识图谱技术等,及其应用产业落地与商业化。
论文有四名共同第一作者:IDEA 研究院资深研究员徐铖晋博士,研究实习生孙嘉硕、汤陆明远和王赛卓。论文通讯作者为 IDEA 研究院郭健博士。除 IDEA 之外,本论文参与方还包括微软亚洲研究院、香港科技大学、香港科技大学(广州)、厦门大学和美国南加州大学。
如想了解 IDEA-HKUST(GZ)联合博士培养项目,请点击。此项目面向全球招生,研究方向聚焦人工智能与数字经济前沿科技。





粤ICP备2020119212号 © 2023年 粤港澳大湾区数字经济研究院(福田)版权所有  粤公网安备 44030402006206号
粤公网安备 44030402006206号

