


日前,国家工业和信息化部“2021 年人工智能产业创新任务揭榜挂帅项目”入围名单正式揭晓,由 IDEA 研究院计算机视觉与机器人研究中心(简称 IDEA 研究院 CVR)独立申报的项目“面向通用预训练模型的超大规模多模态数据库”,经过专家预审、评审、答辩等环节后,最终成功入围。
近年来,预训练大模型大行其道,正成为人工智能赋能各行各业的基础设施。面向通用预训练模型的超大规模数据集,更是“基础设施的基础资源” 。此次 IDEA 研究院 CVR 的入围项目,正是“公共支撑”创新任务中的“人工智能训练资源库”。
目前,计算机视觉领域的主要大规模数据集多出自谷歌、OpenAI、微软等企业和研究机构,而过去几年的研究进展说明,更大的数据集对通用预训练模型及其下游各种应用的性能、质量有显著提升,并能推动更多人工智能模型在产业领域落地应用。我国 2015 年起,已将大数据提升到国家战略资源规划层面,未来,大数据相关软硬件技术将继续快速发展。
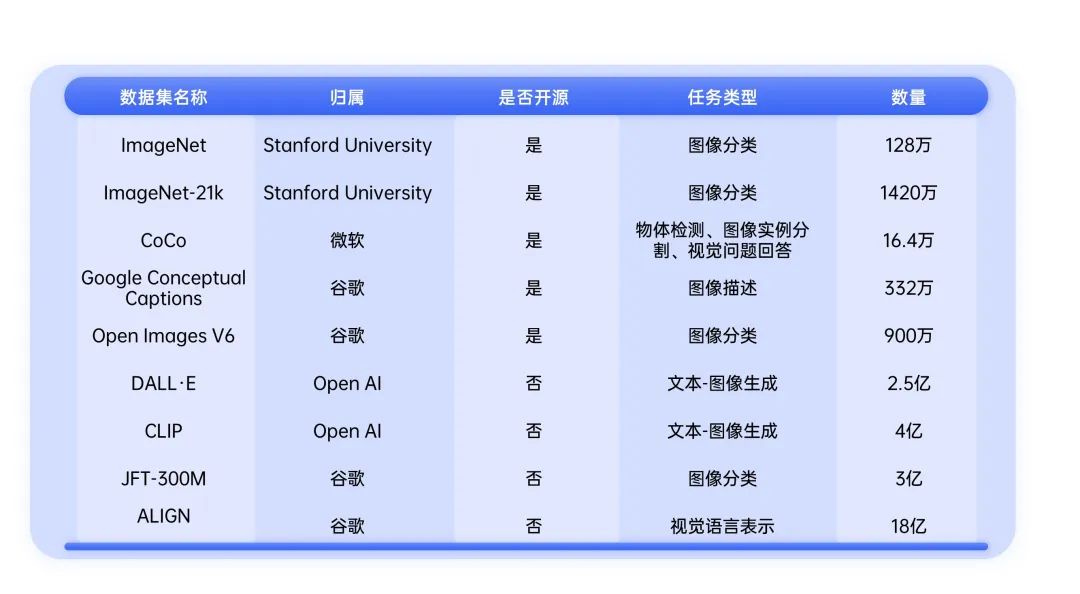
对一般科研机构和中小企业来说,超大规模数据集的构建工作有非常高的门槛。一方面是由于人工智能作为科技竞争的高地,国际上各大公司长期在此领域投资,不断有更大规模的数据集问世。另一方面,构造超大规模数据集需要科研机构和企业负担高昂成本,大数据大模型“烧钱”已成为业界的普遍共识。
基于对未来 20 年中国经济将面临的挑战与机遇的思考,IDEA 研究院组建了相应的研发团队,团队成员具有丰富的图像及多模态数据集构建和使用经验,同时投资建立了大规模数据中心存储和处理数据。IDEA 研究院 CVR 计划构造的超大规模数据资源库及其软硬件服务系统,目标是在数据数量和质量两个方面赶超国际先进水准,同时建设包括数据管理、服务、安全等维度全面自有的软硬件系统。该数据库面向大规模通用预训练模型,将最大限度提高人工智能在实际应用中的效能,并在构建过程中为我国大数据、人工智能行业培养高素质人才。

他曾在微软亚洲研究院、微软总部研究院及计算机视觉相关产品部门任首席研究员,长期带领研究组从事计算机视觉方向的基础研究,包括大规模图像分析、物体检测、视觉语言多模态理解等。
他主导构建过多个大规模图像及多模态数据集,其中 MS-Celeb 1M 是世界最大开源人脸识别训练数据集,在人脸识别研究领域具有很大影响力。他在计算机视觉、多媒体等相关领域发表论文 150 多篇,拥有 60 余项美国授权专利,是人工智能领域的世界级专家。
“揭榜”团队成员拥有微软、DeepMind、腾讯、平安、虎牙等研究与工作经历。他们在过往的研究工作中搭建过多个大规模图像及多模态数据集,且基于数据已做过大量基础性研究工作,并在顶级学术会议期刊上发表过数十篇相关研究成果。同时,算法研究和数据集构建是一个相辅相成的过程,数据质量最终要在基于大模型训练的表示学习中得到验证,早期迭代将非常有助于提高数据质量,该团队在这些方面具有非常好的技术和经验基础。
“面向通用预训练模型的超大规模多模态数据库”项目聚焦于超大规模数据资源库的研发,致力于收集高质量超大规模图像及多模态数据。
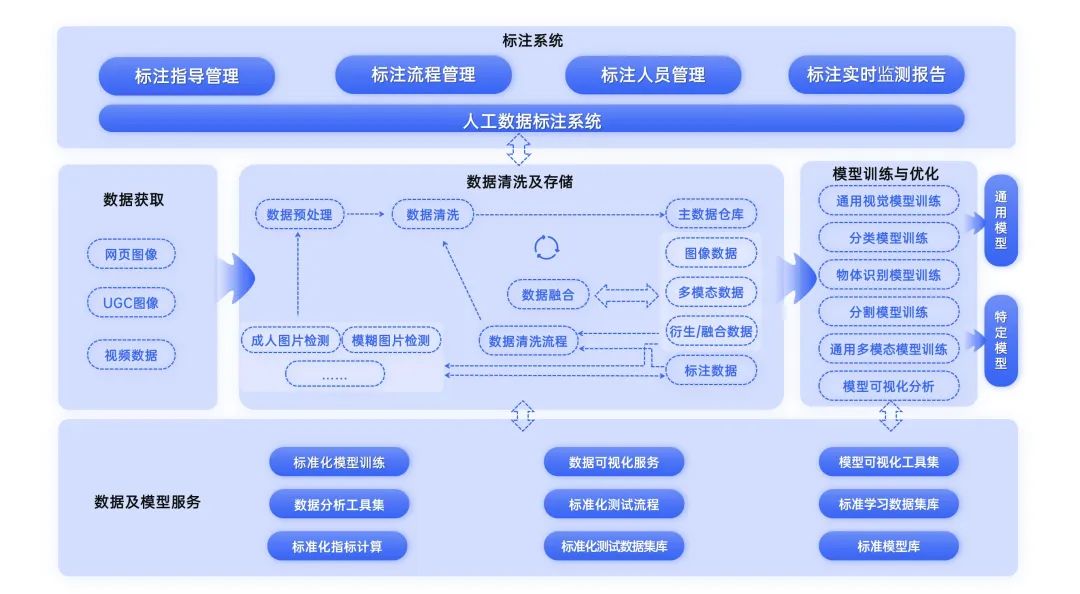
同时,项目团队将基于该数据资源库,建立基础性数据服务平台,作为创新基础设施和多种服务的支撑平台,以支持多种视觉及多模态任务(如物体检测、语义分割、图像描述、图像搜索、图文互搜,基于文本的图像生成等)的数据分析和模型训练任务,为我国人工智能产业的发展添砖加瓦。
日前,国家工业和信息化部“2021 年人工智能产业创新任务揭榜挂帅项目”入围名单正式揭晓,由 IDEA 研究院计算机视觉与机器人研究中心(简称 IDEA 研究院 CVR)独立申报的项目“面向通用预训练模型的超大规模多模态数据库”,经过专家预审、评审、答辩等环节后,最终成功入围。
近年来,预训练大模型大行其道,正成为人工智能赋能各行各业的基础设施。面向通用预训练模型的超大规模数据集,更是“基础设施的基础资源” 。此次 IDEA 研究院 CVR 的入围项目,正是“公共支撑”创新任务中的“人工智能训练资源库”。
目前,计算机视觉领域的主要大规模数据集多出自谷歌、OpenAI、微软等企业和研究机构,而过去几年的研究进展说明,更大的数据集对通用预训练模型及其下游各种应用的性能、质量有显著提升,并能推动更多人工智能模型在产业领域落地应用。我国 2015 年起,已将大数据提升到国家战略资源规划层面,未来,大数据相关软硬件技术将继续快速发展。
对一般科研机构和中小企业来说,超大规模数据集的构建工作有非常高的门槛。一方面是由于人工智能作为科技竞争的高地,国际上各大公司长期在此领域投资,不断有更大规模的数据集问世。另一方面,构造超大规模数据集需要科研机构和企业负担高昂成本,大数据大模型“烧钱”已成为业界的普遍共识。
基于对未来 20 年中国经济将面临的挑战与机遇的思考,IDEA 研究院组建了相应的研发团队,团队成员具有丰富的图像及多模态数据集构建和使用经验,同时投资建立了大规模数据中心存储和处理数据。IDEA 研究院 CVR 计划构造的超大规模数据资源库及其软硬件服务系统,目标是在数据数量和质量两个方面赶超国际先进水准,同时建设包括数据管理、服务、安全等维度全面自有的软硬件系统。该数据库面向大规模通用预训练模型,将最大限度提高人工智能在实际应用中的效能,并在构建过程中为我国大数据、人工智能行业培养高素质人才。
他曾在微软亚洲研究院、微软总部研究院及计算机视觉相关产品部门任首席研究员,长期带领研究组从事计算机视觉方向的基础研究,包括大规模图像分析、物体检测、视觉语言多模态理解等。
他主导构建过多个大规模图像及多模态数据集,其中 MS-Celeb 1M 是世界最大开源人脸识别训练数据集,在人脸识别研究领域具有很大影响力。他在计算机视觉、多媒体等相关领域发表论文 150 多篇,拥有 60 余项美国授权专利,是人工智能领域的世界级专家。
“揭榜”团队成员拥有微软、DeepMind、腾讯、平安、虎牙等研究与工作经历。他们在过往的研究工作中搭建过多个大规模图像及多模态数据集,且基于数据已做过大量基础性研究工作,并在顶级学术会议期刊上发表过数十篇相关研究成果。同时,算法研究和数据集构建是一个相辅相成的过程,数据质量最终要在基于大模型训练的表示学习中得到验证,早期迭代将非常有助于提高数据质量,该团队在这些方面具有非常好的技术和经验基础。
“面向通用预训练模型的超大规模多模态数据库”项目聚焦于超大规模数据资源库的研发,致力于收集高质量超大规模图像及多模态数据。
同时,项目团队将基于该数据资源库,建立基础性数据服务平台,作为创新基础设施和多种服务的支撑平台,以支持多种视觉及多模态任务(如物体检测、语义分割、图像描述、图像搜索、图文互搜,基于文本的图像生成等)的数据分析和模型训练任务,为我国人工智能产业的发展添砖加瓦。





粤ICP备2020119212号 © 2023年 粤港澳大湾区数字经济研究院(福田)版权所有  粤公网安备 44030402006206号
粤公网安备 44030402006206号

