


ICLR 全称 International Conference on Learning Representation,由图灵奖获得者 Yoshua Bengio 和 Yann LeCun 牵头举办。该会议广受认可,被认为是深度学习领域的顶级会议。
ICLR 2024 于今年五月初在奥地利维也纳顺利闭幕。相较于往年,无论是参会人数还是论文提交量,ICLR 的热度均极大提升。IDEA 研究院有 8 篇论文被收录。
本期 Paper Sparks 为大家详细介绍 IDEA 研究院近期的亮点研究。
ICLR 论文主题一览
· GPAvatar:利用极少训练数据实现高保真的身份重建、精确的表情控制和多视角一致性
· Progressive3D:用语义复杂的文本提示生成准确的 3D 内容
· SymPoint:简单高效地从 CAD 矢量图中识别和解析可数对象实例和不可数材料
· Direct Inversion:在图片编辑中保持背景的稳定性,并对前景进行定制化调整
· PromptMSP:扩展 PPI 知识至各规模多聚体,优化结构预测的准确度与速度
· TOSS:引入文本描述,提升从单照片生成多角度图像的可控性和合理性
· DreamTime:对齐 3D 优化与扩散模型的采样过程,使创作过程更便捷和普及
· Tag2Text:通过无监督训练获取强大的图像标签能力,并可用于引导图像标题生成
01

虚拟人的头部重建在虚拟现实、在线会议、游戏和电影产业等场景中至关重要。本文提出了一个 GPAvatar 框架,可以利用单张或多张输入图片重建 3D 头像,弥补传统方法需要大量训练数据的不足。
此框架的关键是引入动态的基于点的表情场(Point-based Expression Field,PEF),能精确并高效地捕捉表情,为生成更加丰富的面部表情提供了基础。论文还提出了 Multi Tri-planes Attention(MTA)融合模块,可以接受任意数量的输入图像,在推理过程中整合更多信息,特别有利于处理极端输入,如闭眼和遮挡等。

GPAvatar 效果展示:在每组人像中,最左边是输入图像,右边是再现的结果。插图显示了相应的驱动脸部。此外,第一行展示了三个新视角合成结果。
通过使用 VFHQ 和 HDTF 等公认的基准数据集进行评估,GPAvatar 框架在不同指数上优于现有技术。实现了高保真的身份重建、精确的表情控制和多视角一致性,展现了在虚拟空间任意视角下,渲染出动态头像 avatar 的应用潜力。
本项工作由东京大学、IDEA 研究院和日本理化学研究所共同完成。
论文地址
代码地址
02

在从文本到 3D 内容创造(text-to-3D content creation)的过程中,当给定的文本提示(prompt)在语义上非常复杂时,现有的生成方法难以生成正确的 3D 内容。本文提出了一种名为 Progressive3D 的通用编辑框架,可以将复杂的生成过程分解为一系列局部的编辑步骤来生成准确的 3D 内容。
具体来说,当文本提示描述了多个交互的且具有不同属性的物体,Progressive3D 会限制每次编辑内容的变换只能发生在用户定义的 3D 空间内,并提出了内容一致性约束(consistency constraint),以保持选定区域之外的内容不变,从而逐步生成目标对象及其属性。此外,论文设计了一种重叠语义分量抑制(Overlapped Semantic Component Suppression, OSCS)的技术,来自动探索源提示和目标提示之间的语义差异,并在优化过程中抑制重叠的语义组件,从而更专注于两个提示之间的区别。

Progressive3D 的效果展示:在复杂的文本提示下,使用了 Progressive3D 的生成效果(b)比使用了传统生成方法(a)要准确。
论文通过一系列实验,包括使用了一个包含 100 个不同复杂提示的数据集 CSP-100 和两个细粒度指标 BLIP-VQA 和 mGPT-CoT,证明了 Progressive3D 在创建与复杂语义提示一致的精确 3D 内容方面的有效性。此外,Progressive3D 不仅限于特定的 3D 表示方法,它与多种基于不同 3D 神经表示的文本到 3D 方法兼容,增强了其通用性和实用性,可以更方便且高效地完成用户指令。
本项工作由 IDEA 研究院、北京大学和鹏城实验室共同完成。
03

在设计图纸的审查和 3D 建筑信息的建模(BIM)过程中,如何从 CAD 矢量图中解析并识别出目标符号(例如门、窗、桌子,墙壁以及栏杆等)是十分重要的一步,也是计算机视觉领域中的一个特定问题,即全景符号识别(panoptic symbol spotting)。
对比于传统的将矢量图转换为图像再进行识别的方法,本文提出了一种基于点集表示的 CAD 矢量图识别方法 SymPoint。它使用点云 transformer 提取图元特征,然后经过符号定位网络输出最终识别结果。新方法能够很好地处理图元的随意分布的不规则性,同时降低计算复杂性。
此外,为了更好地利用图元之间的局部连接信息并增强它们的可区分性,论文提出了带有连接模块的注意力机制(Attention with Connection Module, ACM)和对比连接学习机制(Contrastive Connection Learning, CCL)。论文的最后还提出了一种 KNN 插值机制,用于缓解符号定位网络中的注意力掩码在降采样过程中存在的信息丢失问题。
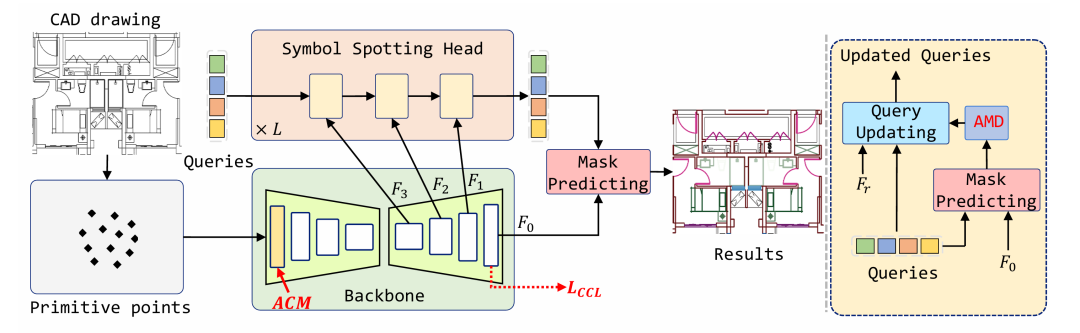
SymPoint 的方法框架。
SymPoint 在 FloorPlanCAD 数据集上进行了广泛的实验,并且取得了 83.3%的 PQ(Panoptic Quality)和 91.1%的 RQ(Recognition Quality),大幅超越现有的最先进的方法。在室内设计、室内建筑和房地产开发等需要准确识别大量图纸的领域中,使用该方法可以快速高效且资源消耗小地达到要求。
本项工作由 IDEA 研究院和万翼科技共同完成。
04

基于扩散模型的图像生成与编辑让创作者无需受传统摄影或平面设计的限制,都可以创造出针对特定受众的引人注目的内容。本论文在如何提高图像编辑的质量和效率,尤其是在保持源图像的重要内容和确保编辑保真度上,提出了一个新颖的方法,Direct Inversion(直接反演)。
Direct Inversion 用于提升图片编辑中的背景不变性和前景按照需求可控性,其核心思想是将源分支和目标分支分离,让每个分支专注于其指定的角色:维持不变或开始编辑。该技术仅使用三行代码就可以直接在源扩散分支内校正反演偏差,同时保持目标扩散分支不变,以确保根据目标提示实现最佳的编辑保真度。

将 Direct Inversion 合并到四种基于扩散的编辑方法中的性能增强,这些方法跨越各种编辑类别(从上到下):样式转换、对象替换和颜色更改。
为了系统地评估图像编辑性能,论文介绍了 PIE Bench:一个编辑基准,以 700 幅不同场景和编辑类型的图像为特色,并辅以多功能注释。根据结果,与现有的方法相比,Direct Inversion 不仅在 8 种编辑方法中提供了更优越的性能,而且实现了将近一个数量级的加速。
该方法的编辑性能和推理速度,在广告和媒体行业、教育和科学可视化领域以及娱乐和艺术领域都有应用潜力。
本项工作由香港中文大学和 IDEA 研究院共同完成。
05

3D 结构的蛋白质多聚体在调控众多细胞功能中扮演着关键角色。通过利用已知的二聚体结构信息和预测的蛋白质-蛋白质相互作用(PPI)数据,我们可以采用逐步组装的方法高效地预测多聚体的三维构型。
然而,由于二聚体和更大的多聚体形成方面的生物学差距,直接应用 PPI 预测技术通常会导致该任务的泛化性较差。为了应对这一挑战,论文提出了用于多聚体结构预测的预训练和微调框架 PromptMSP,目标将 PPI 知识扩展到不同规模(即链数)的多聚体。
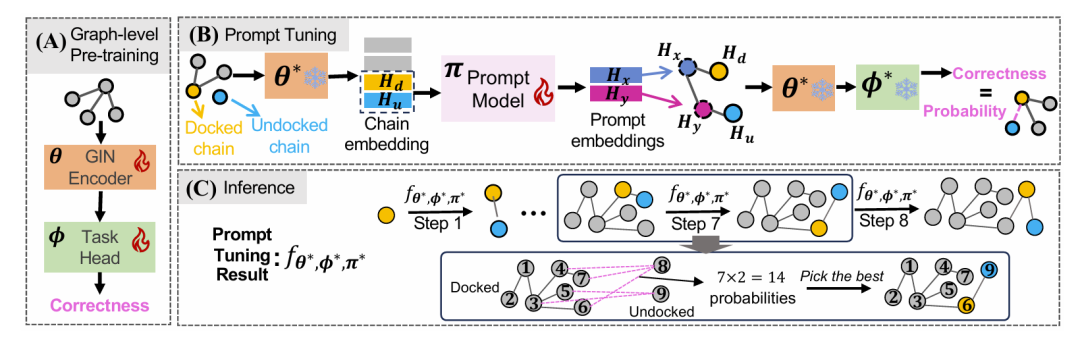
PromptMSP 的方法框架,一共分为三个步骤。
PromptMSP 的核心思想是通过预训练和提示学习来弥合不同规模(即链数量)的多聚体数据之间的差距,并将任意规模的多聚体转化为固定规模的多聚体进行处理,从而提高多聚体结构预测(MSP)的准确性和效率。采用了元学习(MAML)框架来增强提示调整过程,以实现在大规模多聚体的有限数据。
根据 PromptMSP 在不同规模的多聚体数据集上的泛化效果,新方法在对蛋白多聚体结构进行预测的准确性和效率上都显著优于目前 SOTA 模型。这一方法在理解细胞过程、疾病机理和药物发现等方面都有很大的应用空间。
本项工作由香港科技大学(广州)、香港科技大学、香港中文大学和 IDEA 研究院共同完成。
06

单视图新视角生成任务(NVS from a single image)的目标是在给定一张任意物体的 RGB 图像后,生成该物体任意新视角的图像。现有的生成方法通常会生成语义不合理的几何形状或纹理。其根本原因是该任务是一个欠约束问题,即未被观测到的几何形状和纹理存在多种可能的求解结果。由于新视角的解空间过大,导致无法保证生成结果的合理性。为了生成合理的新视角图像,同时满足用户能有更多的途径来控制生成的结果,论文提出了将文本描述信息引入到单视图新视角生成任务的方法 TOSS (Text-Guided Novel View Synthesis) 。
文本作为高级语义信息可以对物体的不可见部分施加约束,进一步缩小新视角的解空间。同时与单视图提供的底层细节互补,帮助生成语义更合理的结果。用户可以自主细化文本的关注点和描述粒度生成满足期望的结果。
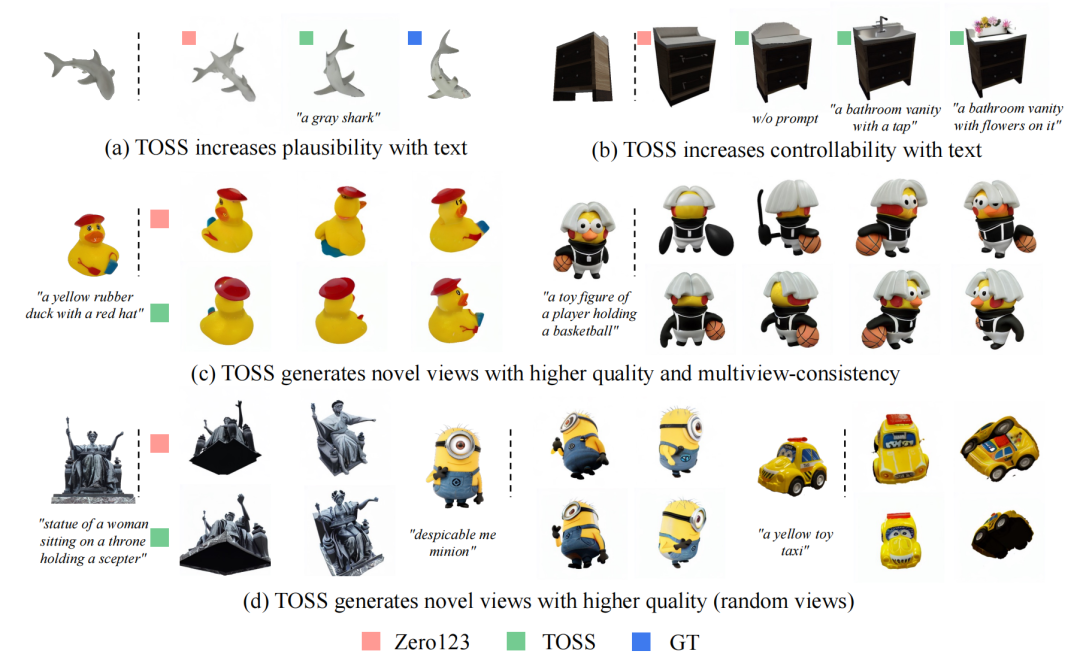
TOSS 通过引入的文本信息,(a) 提升了生成图像的合理性,(b) 有更好的可控性,(c)生成高质量且多角度一致的环视视图的新视角图像,(d)即使生成随机视角的图像,也有更高的图片质量。
TOSS使用密集交叉注意力模块和训练策略,专注于新视角的姿态正确性和细节保留,从而生成高质量的图像。通过与 Zero123 和 GT 方法生成的图像对比,TOSS 的生成结果语义更合理且可控性更强,为动漫角色生成、虚拟现实和电影工业领域提供了新解法。
本项工作由清华大学、香港科技大学和 IDEA 研究院共同完成。
07

传统的 3D 建模昂贵费时,需要具有丰富美学和 3D 建模知识的专业人士耗费大量时间制作。为了实现无需人工参与的自动化生成 3D,现有的方法一般会利用预训练的图像生成扩散模型进行得分蒸馏采样(Score Distillation Sampling,SDS)。然而,该生成过程依赖于收敛缓慢的优化训练。由于优化过程与 SDS 中使用的均匀时间步采样之间的冲突,生成的 3D 模型通常存在质量问题或生成内容的多样性不足。
针对这两个局限,本文提出使用时间优先得分蒸馏采样(Time Prioritized Score Distillation Sampling, TP-SDS)的方法,DreamTime。这是一种简单有效的单调非递增时间步数(timestep)采样策略,能够对齐 3D 优化与扩散模型的采样过程,避免模式崩塌。
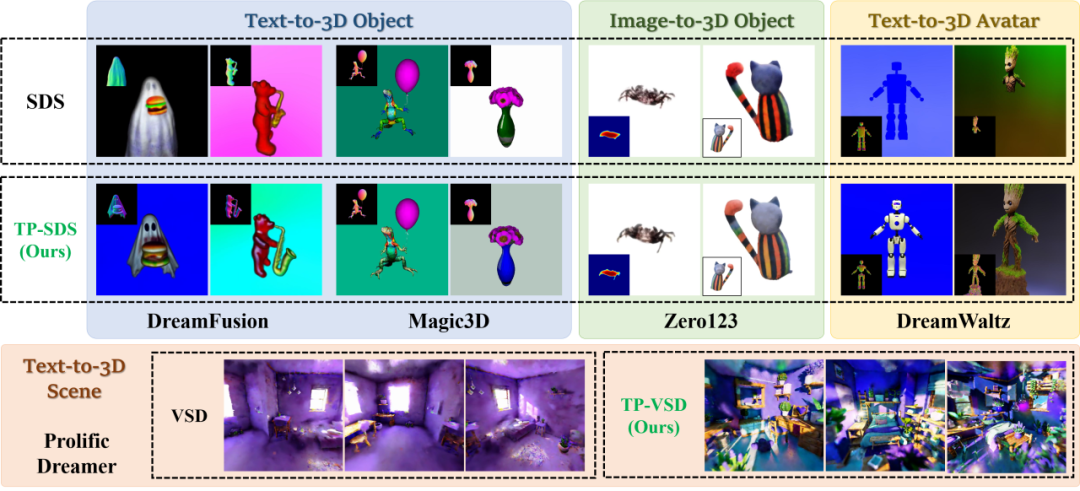
DreamTime 能够在多种框架和应用场景中实现更高质量的 3D 生成。
DreamTime 在 3D 物体、3D 数字人、3D 场景等多种生成设置上进行了广泛的实验,证明该方法能够显著提高 3D 内容生成的质量,生成效率和多样性,并且不增加计算和内存负担。
在仿真机器人、游戏和沉浸式媒体等应用场景,该研究可以使创作过程更加便捷和普及,促使非专业人士也能轻松参与 3D 内容的创作,分享他们的视角和创意,从而进一步推动数字内容领域的繁荣与多样化。
本项工作由 IDEA 研究院和香港大学共同完成。
08

视觉-语言预训练(Vision language pre-training, VLP)是一种有效的学习多模态表达的方法,并且可以提高视觉语言任务的性能,包括基于生成和基于对齐的任务。但现有的 VLP 由于训练过程中缺乏细粒度的对齐信息,并缺乏足够的可控性,导致在实际应用中难以落地。本文提出了名为 Tag2Text 的 VLP 框架,旨在通过引入图像标签(Image Tagging)来引导视觉-语言模型学习相关特征。
与传统依赖手工标注的小规模标签数据的 VLP 方法不同,Tag2Text 通过自动化解析图像的配对文本,获取图像标签,从而训练出了具有强大泛化能力的标签模型。这意味着 Tag2Text 能够进行大规模无监督图像标记,提供多样化的标签类别,如场景、属性、动作等。同时利用其强大的标签能力作为引导信息,生成细粒度、广泛且可控的图像描述信息。

对比 Tag2Text 和 BLIP 的图片描述能力。Tag2Text 将识别到的图像标签作为引导元素整合到文本生成中,从而生成更为全面的文本描述。
Tag2Text 在 COCO 和 OpenImages 等测试集上进行了实验验证,结果表明Tag2Text 在数据规模更小(14M)的情况下,超越了现有数据规模更大的视觉-语言模型,如 CLIP(OpenAI, 400M)和 BLIP2(Salesforce, 129M)。不仅如此,Tag2Text 还允许用户输入特定的标签来生成相应的标题,提供了一种通过使用输入标签来控制标题生成的方法,展现了其在应用场景的实用性。
本项工作由复旦大学、OPPO 研究院和 IDEA 研究院共同完成。
ICLR 全称 International Conference on Learning Representation,由图灵奖获得者 Yoshua Bengio 和 Yann LeCun 牵头举办。该会议广受认可,被认为是深度学习领域的顶级会议。
ICLR 2024 于今年五月初在奥地利维也纳顺利闭幕。相较于往年,无论是参会人数还是论文提交量,ICLR 的热度均极大提升。IDEA 研究院有 8 篇论文被收录。
本期 Paper Sparks 为大家详细介绍 IDEA 研究院近期的亮点研究。
ICLR 论文主题一览
· GPAvatar:利用极少训练数据实现高保真的身份重建、精确的表情控制和多视角一致性
· Progressive3D:用语义复杂的文本提示生成准确的 3D 内容
· SymPoint:简单高效地从 CAD 矢量图中识别和解析可数对象实例和不可数材料
· Direct Inversion:在图片编辑中保持背景的稳定性,并对前景进行定制化调整
· PromptMSP:扩展 PPI 知识至各规模多聚体,优化结构预测的准确度与速度
· TOSS:引入文本描述,提升从单照片生成多角度图像的可控性和合理性
· DreamTime:对齐 3D 优化与扩散模型的采样过程,使创作过程更便捷和普及
· Tag2Text:通过无监督训练获取强大的图像标签能力,并可用于引导图像标题生成
01
虚拟人的头部重建在虚拟现实、在线会议、游戏和电影产业等场景中至关重要。本文提出了一个 GPAvatar 框架,可以利用单张或多张输入图片重建 3D 头像,弥补传统方法需要大量训练数据的不足。
此框架的关键是引入动态的基于点的表情场(Point-based Expression Field,PEF),能精确并高效地捕捉表情,为生成更加丰富的面部表情提供了基础。论文还提出了 Multi Tri-planes Attention(MTA)融合模块,可以接受任意数量的输入图像,在推理过程中整合更多信息,特别有利于处理极端输入,如闭眼和遮挡等。
GPAvatar 效果展示:在每组人像中,最左边是输入图像,右边是再现的结果。插图显示了相应的驱动脸部。此外,第一行展示了三个新视角合成结果。
通过使用 VFHQ 和 HDTF 等公认的基准数据集进行评估,GPAvatar 框架在不同指数上优于现有技术。实现了高保真的身份重建、精确的表情控制和多视角一致性,展现了在虚拟空间任意视角下,渲染出动态头像 avatar 的应用潜力。
本项工作由东京大学、IDEA 研究院和日本理化学研究所共同完成。
论文地址
代码地址
02
在从文本到 3D 内容创造(text-to-3D content creation)的过程中,当给定的文本提示(prompt)在语义上非常复杂时,现有的生成方法难以生成正确的 3D 内容。本文提出了一种名为 Progressive3D 的通用编辑框架,可以将复杂的生成过程分解为一系列局部的编辑步骤来生成准确的 3D 内容。
具体来说,当文本提示描述了多个交互的且具有不同属性的物体,Progressive3D 会限制每次编辑内容的变换只能发生在用户定义的 3D 空间内,并提出了内容一致性约束(consistency constraint),以保持选定区域之外的内容不变,从而逐步生成目标对象及其属性。此外,论文设计了一种重叠语义分量抑制(Overlapped Semantic Component Suppression, OSCS)的技术,来自动探索源提示和目标提示之间的语义差异,并在优化过程中抑制重叠的语义组件,从而更专注于两个提示之间的区别。
Progressive3D 的效果展示:在复杂的文本提示下,使用了 Progressive3D 的生成效果(b)比使用了传统生成方法(a)要准确。
论文通过一系列实验,包括使用了一个包含 100 个不同复杂提示的数据集 CSP-100 和两个细粒度指标 BLIP-VQA 和 mGPT-CoT,证明了 Progressive3D 在创建与复杂语义提示一致的精确 3D 内容方面的有效性。此外,Progressive3D 不仅限于特定的 3D 表示方法,它与多种基于不同 3D 神经表示的文本到 3D 方法兼容,增强了其通用性和实用性,可以更方便且高效地完成用户指令。
本项工作由 IDEA 研究院、北京大学和鹏城实验室共同完成。
03
在设计图纸的审查和 3D 建筑信息的建模(BIM)过程中,如何从 CAD 矢量图中解析并识别出目标符号(例如门、窗、桌子,墙壁以及栏杆等)是十分重要的一步,也是计算机视觉领域中的一个特定问题,即全景符号识别(panoptic symbol spotting)。
对比于传统的将矢量图转换为图像再进行识别的方法,本文提出了一种基于点集表示的 CAD 矢量图识别方法 SymPoint。它使用点云 transformer 提取图元特征,然后经过符号定位网络输出最终识别结果。新方法能够很好地处理图元的随意分布的不规则性,同时降低计算复杂性。
此外,为了更好地利用图元之间的局部连接信息并增强它们的可区分性,论文提出了带有连接模块的注意力机制(Attention with Connection Module, ACM)和对比连接学习机制(Contrastive Connection Learning, CCL)。论文的最后还提出了一种 KNN 插值机制,用于缓解符号定位网络中的注意力掩码在降采样过程中存在的信息丢失问题。
SymPoint 的方法框架。
SymPoint 在 FloorPlanCAD 数据集上进行了广泛的实验,并且取得了 83.3%的 PQ(Panoptic Quality)和 91.1%的 RQ(Recognition Quality),大幅超越现有的最先进的方法。在室内设计、室内建筑和房地产开发等需要准确识别大量图纸的领域中,使用该方法可以快速高效且资源消耗小地达到要求。
本项工作由 IDEA 研究院和万翼科技共同完成。
04
基于扩散模型的图像生成与编辑让创作者无需受传统摄影或平面设计的限制,都可以创造出针对特定受众的引人注目的内容。本论文在如何提高图像编辑的质量和效率,尤其是在保持源图像的重要内容和确保编辑保真度上,提出了一个新颖的方法,Direct Inversion(直接反演)。
Direct Inversion 用于提升图片编辑中的背景不变性和前景按照需求可控性,其核心思想是将源分支和目标分支分离,让每个分支专注于其指定的角色:维持不变或开始编辑。该技术仅使用三行代码就可以直接在源扩散分支内校正反演偏差,同时保持目标扩散分支不变,以确保根据目标提示实现最佳的编辑保真度。
将 Direct Inversion 合并到四种基于扩散的编辑方法中的性能增强,这些方法跨越各种编辑类别(从上到下):样式转换、对象替换和颜色更改。
为了系统地评估图像编辑性能,论文介绍了 PIE Bench:一个编辑基准,以 700 幅不同场景和编辑类型的图像为特色,并辅以多功能注释。根据结果,与现有的方法相比,Direct Inversion 不仅在 8 种编辑方法中提供了更优越的性能,而且实现了将近一个数量级的加速。
该方法的编辑性能和推理速度,在广告和媒体行业、教育和科学可视化领域以及娱乐和艺术领域都有应用潜力。
本项工作由香港中文大学和 IDEA 研究院共同完成。
05
3D 结构的蛋白质多聚体在调控众多细胞功能中扮演着关键角色。通过利用已知的二聚体结构信息和预测的蛋白质-蛋白质相互作用(PPI)数据,我们可以采用逐步组装的方法高效地预测多聚体的三维构型。
然而,由于二聚体和更大的多聚体形成方面的生物学差距,直接应用 PPI 预测技术通常会导致该任务的泛化性较差。为了应对这一挑战,论文提出了用于多聚体结构预测的预训练和微调框架 PromptMSP,目标将 PPI 知识扩展到不同规模(即链数)的多聚体。
PromptMSP 的方法框架,一共分为三个步骤。
PromptMSP 的核心思想是通过预训练和提示学习来弥合不同规模(即链数量)的多聚体数据之间的差距,并将任意规模的多聚体转化为固定规模的多聚体进行处理,从而提高多聚体结构预测(MSP)的准确性和效率。采用了元学习(MAML)框架来增强提示调整过程,以实现在大规模多聚体的有限数据。
根据 PromptMSP 在不同规模的多聚体数据集上的泛化效果,新方法在对蛋白多聚体结构进行预测的准确性和效率上都显著优于目前 SOTA 模型。这一方法在理解细胞过程、疾病机理和药物发现等方面都有很大的应用空间。
本项工作由香港科技大学(广州)、香港科技大学、香港中文大学和 IDEA 研究院共同完成。
06
单视图新视角生成任务(NVS from a single image)的目标是在给定一张任意物体的 RGB 图像后,生成该物体任意新视角的图像。现有的生成方法通常会生成语义不合理的几何形状或纹理。其根本原因是该任务是一个欠约束问题,即未被观测到的几何形状和纹理存在多种可能的求解结果。由于新视角的解空间过大,导致无法保证生成结果的合理性。为了生成合理的新视角图像,同时满足用户能有更多的途径来控制生成的结果,论文提出了将文本描述信息引入到单视图新视角生成任务的方法 TOSS (Text-Guided Novel View Synthesis) 。
文本作为高级语义信息可以对物体的不可见部分施加约束,进一步缩小新视角的解空间。同时与单视图提供的底层细节互补,帮助生成语义更合理的结果。用户可以自主细化文本的关注点和描述粒度生成满足期望的结果。
TOSS 通过引入的文本信息,(a) 提升了生成图像的合理性,(b) 有更好的可控性,(c)生成高质量且多角度一致的环视视图的新视角图像,(d)即使生成随机视角的图像,也有更高的图片质量。
TOSS使用密集交叉注意力模块和训练策略,专注于新视角的姿态正确性和细节保留,从而生成高质量的图像。通过与 Zero123 和 GT 方法生成的图像对比,TOSS 的生成结果语义更合理且可控性更强,为动漫角色生成、虚拟现实和电影工业领域提供了新解法。
本项工作由清华大学、香港科技大学和 IDEA 研究院共同完成。
07
传统的 3D 建模昂贵费时,需要具有丰富美学和 3D 建模知识的专业人士耗费大量时间制作。为了实现无需人工参与的自动化生成 3D,现有的方法一般会利用预训练的图像生成扩散模型进行得分蒸馏采样(Score Distillation Sampling,SDS)。然而,该生成过程依赖于收敛缓慢的优化训练。由于优化过程与 SDS 中使用的均匀时间步采样之间的冲突,生成的 3D 模型通常存在质量问题或生成内容的多样性不足。
针对这两个局限,本文提出使用时间优先得分蒸馏采样(Time Prioritized Score Distillation Sampling, TP-SDS)的方法,DreamTime。这是一种简单有效的单调非递增时间步数(timestep)采样策略,能够对齐 3D 优化与扩散模型的采样过程,避免模式崩塌。
DreamTime 能够在多种框架和应用场景中实现更高质量的 3D 生成。
DreamTime 在 3D 物体、3D 数字人、3D 场景等多种生成设置上进行了广泛的实验,证明该方法能够显著提高 3D 内容生成的质量,生成效率和多样性,并且不增加计算和内存负担。
在仿真机器人、游戏和沉浸式媒体等应用场景,该研究可以使创作过程更加便捷和普及,促使非专业人士也能轻松参与 3D 内容的创作,分享他们的视角和创意,从而进一步推动数字内容领域的繁荣与多样化。
本项工作由 IDEA 研究院和香港大学共同完成。
08
视觉-语言预训练(Vision language pre-training, VLP)是一种有效的学习多模态表达的方法,并且可以提高视觉语言任务的性能,包括基于生成和基于对齐的任务。但现有的 VLP 由于训练过程中缺乏细粒度的对齐信息,并缺乏足够的可控性,导致在实际应用中难以落地。本文提出了名为 Tag2Text 的 VLP 框架,旨在通过引入图像标签(Image Tagging)来引导视觉-语言模型学习相关特征。
与传统依赖手工标注的小规模标签数据的 VLP 方法不同,Tag2Text 通过自动化解析图像的配对文本,获取图像标签,从而训练出了具有强大泛化能力的标签模型。这意味着 Tag2Text 能够进行大规模无监督图像标记,提供多样化的标签类别,如场景、属性、动作等。同时利用其强大的标签能力作为引导信息,生成细粒度、广泛且可控的图像描述信息。
对比 Tag2Text 和 BLIP 的图片描述能力。Tag2Text 将识别到的图像标签作为引导元素整合到文本生成中,从而生成更为全面的文本描述。
Tag2Text 在 COCO 和 OpenImages 等测试集上进行了实验验证,结果表明Tag2Text 在数据规模更小(14M)的情况下,超越了现有数据规模更大的视觉-语言模型,如 CLIP(OpenAI, 400M)和 BLIP2(Salesforce, 129M)。不仅如此,Tag2Text 还允许用户输入特定的标签来生成相应的标题,提供了一种通过使用输入标签来控制标题生成的方法,展现了其在应用场景的实用性。
本项工作由复旦大学、OPPO 研究院和 IDEA 研究院共同完成。





粤ICP备2020119212号 © 2023年 粤港澳大湾区数字经济研究院(福田)版权所有  粤公网安备 44030402006206号
粤公网安备 44030402006206号

