


9 月 1 至 3 日,2022 世界人工智能大会(简称 WAIC)在上海举办。在阿里巴巴达摩院主办的“大规模预训练模型”主题论坛上,IDEA 研究院认知计算与自然语言研究中心讲席科学家张家兴受邀发表了“预训练大模型时代的 AI 新范式”主题演讲。
论坛上,张家兴与阿里巴巴达摩院副院长周靖人、澜舟科技创始人周明、清华大学教授唐杰、深势科技创始人张林峰等在学术界、产业界中深耕大模型领域的思想引领者们,共同围绕“大规模预训练模型的创新、落地和开源开放”进行深入讨论,展示了国产大模型多元生态下的技术成果和思考。

过去两年,预训练模型的参数规模以前所未有的速度膨胀,在海量的无监督学习已能实现“感知智能”的今天,学者们更多地在思考如何推动 AI 表现出更加类人的推理和思考能力,让大模型带领人工智能走向“认知智能”时代。
大模型时代将给认知智能带来什么样的技术新范式?张家兴从“先验”、“闭环”、“大模型开源”和“AI 生产 AI”四个角度分享了他的思考,并展示他与团队的最新研究成果。

经过了数百万年的进化,每个呱呱坠地的人类婴儿都自带一个“出厂格式”,即只需要很少次数的样本示例就可以学会某个技能,甚至在没有样本的情况下也能无师自通,这就是先验。
预训练大模型让 AI 拥有了先验,并能越来越高效地学习,完成各种指定任务。张家兴思考,除了提升模型先验能力,让 AI 完成各种下游任务,是否还能在先验与下游任务之间,找到一种能让 AI 任务经验能更好地被反馈、迭代,并实现更高效积累、增长的方案?
他提出,在预训练大模型与下游任务间存在着一种“任务的表现型”。以分类任务举例,BERT 可以通过 classification 的方式选择 Label,T5 可以 seq2seq 的方式生成 Label,GPT 也可以直接通过 LM 的方式生成 Label。实际上预训练中的很多工作,就是在预训练大模型上选择或创造一种“表现型”,让大模型与各种下游任务彼此相适应。
UnifiedMC 就是张家兴携团队(IDEA 研究院认知计算与自然语言中心,简称 IDEA 研究院 CCNL),针对自然语言理解任务提出的一种新的表现型。
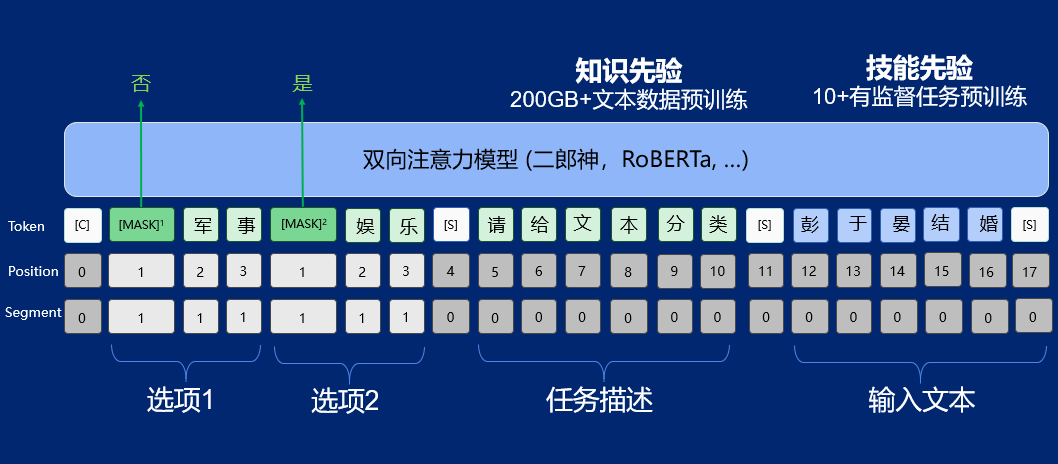
双向注意力模型通常在同等算力情况下能达到比生成模型更好的性能,以双向注意力模型为基础的 UnifiedMC,进一步通过将标签作为多选项作输入,提升了模型性能,以 2 亿的参数规模,就可达到谷歌的 5400 亿 PaLM 模型性能。
除了如何让大模型更好地适应文本分类等下游任务,他还在关注大模型在文本生成类任务上,能否通过推理能力的多步叠加,实现推理经验的增长,从而推动「AI 推理」无限接近「人的思考」。张家兴现场演示了 AI 根据「机器人统治世界」的输入,所展开的推理过程。经过一连串推理,AI 得出的结论是「人类要使用高能量武器消灭机器人」。
张家兴认为,“也许人类的思考,本质上就是无限的因果推理。而无限的多步推理,是机器的自主思考。”
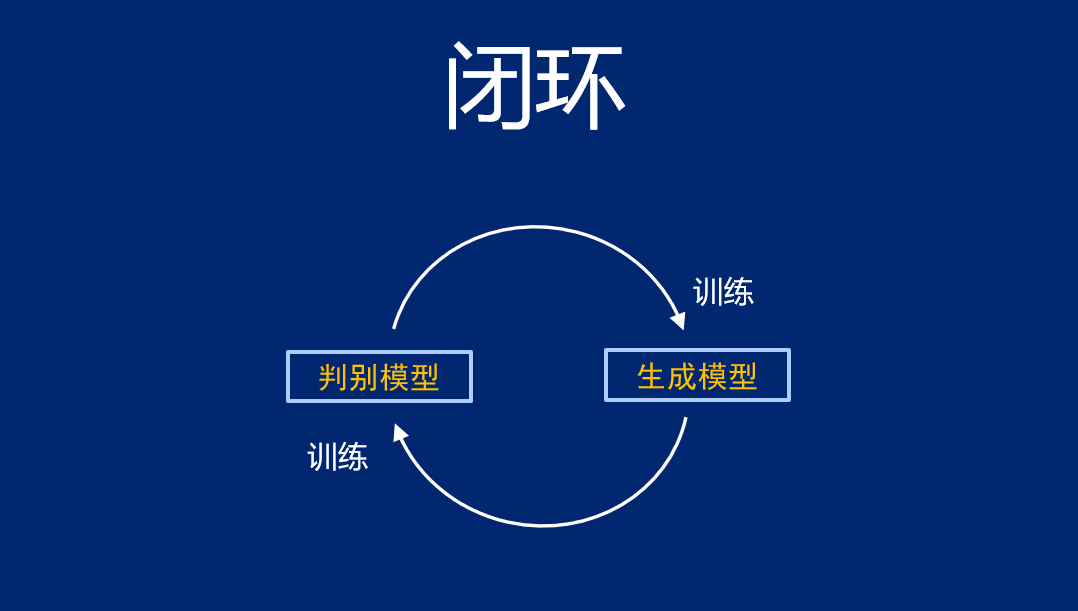
在自然语言处理领域,许多人正在尝试构造训练的闭环,比如用生成模型生成数据,构建判别模型,再把判断返还给生成模型,让模型自己跟自己学,不再依赖人的数据输入。张家兴也在从事这一问题的研究,论坛上,他引用哲学家维特根斯坦的“语言游戏”说——人对语言的理解无非都来自于语言游戏,人和人之间形成一个闭环,最终理解了语言的意义。
“我们认为每个闭环的设计,都是一个语言游戏的设计(合作行为语言游戏)。所以提出了合作闭环模式。”张家兴表示,生成模型与判别模型间的合作,可能比对抗更能帮助研究者们构造出有效的闭环。
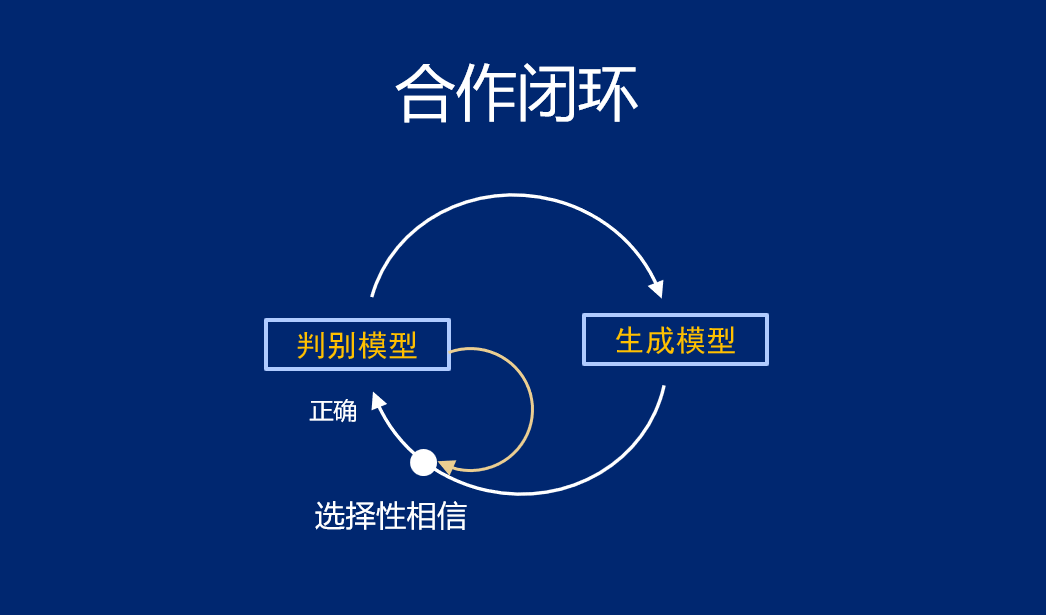
“我们设计了多种闭环,这套闭环设计,可以在 SOTA 模型的基础上再实现 1~2 个点的效果提升,”他在现场展示了一组性能数据,“过去很多人试过,效果都不太好。但为什么现在闭环成为了可能?因为预训练大模型给了 AI 更好的文本生成能力,给了闭环更好的「初始化」。”
预训练大模型作为认知智能的基石,被称为人工智能的大脑。预训练大模型的开源,对人工智能技术的整体演进意义非凡。
“下面我要展示的这两个榜单,正如刚刚周明教授所说,在座的各位嘉宾都是榜上常客了。”张家兴现场展示了 FewCLUE(小样本学习)和 ZeroCLUE(零样本学习)的榜单实况,封神榜开源大模型体系下的“二郎神”在两个榜单上同时登顶,澜舟的“孟子”、智源的“天枢”等选手紧随其后。
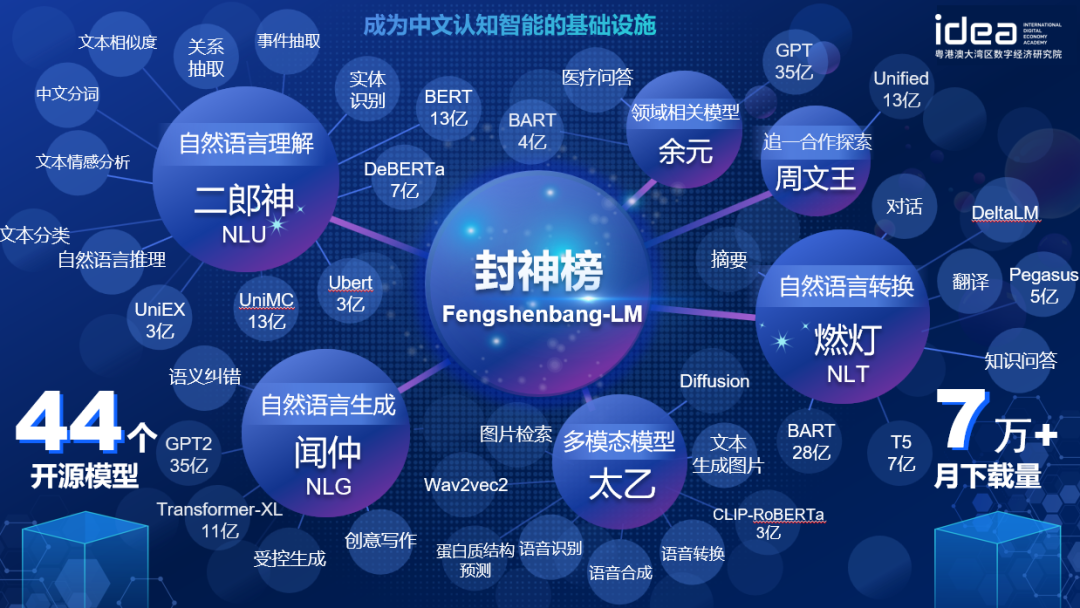
IDEA 研究院 CCNL 团队于 2021 年 11 月推出了封神榜系列开源大模型,随后又推出了封神框架。封神榜全方面开源一系列预训练大模型,目前已覆盖文本理解、文本摘要、文本生成、多模态生成等相关任务,致力于为工业界和学术界提供简单高效的解决方案。封神框架则提供丰富、真实的源代码和示例,用以模型训练及应用。
目前,封神榜系列开源大模型中的二郎神系列已获得数个中文榜单 SOTA 成绩。未来,封神榜还将持续更新。张家兴表示,希望更多公司、高校、机构能加入到这一开源行动,共建中文认知智能的基础设施。
大模型落地也是学工界共同关注的重要议题。
今天,那些应用在具体场景里的 AI 技术,为千行百业的数字化进程打下了良好的基础,但原有 AI 生产模式的不足也在落地过程中逐渐暴露。专用 AI 模型,往往由算法工程师“手工”编写。培养一个经验丰富的算法工程师周期长、难度大,生产过程对数据的要求也很高。成本高企,效益不明,这两个风险阻碍许多企业投身 AI 浪潮。
“用 AI 生产 AI 模型,可以解决现在 AI 模型落地成本过高、数据稀缺的问题。”张家兴介绍,GTSfactory AI 模型生产平台由 CCNL 团队自主开发,以具有高通用性和泛化能力的封神榜系列预训练大模型为底座,结合团队的 AI 系统工程能力,自动化生产出一个个小模型。

GTSfactory 有一套核心的复杂生产体系,Generator、Teacher、Student 是三种不同规模的预训练模型。Generator 利用预训练大模型强大的文本生成能力,为训练任务生成更多的训练样本。Teacher 利用预训练大模型天然的少样本学习能力,指导整个训练过程。Student 是用户可下载的轻量模型,综合了包括元学习、增量学习、半监督学习、预训练、自训练等各种机器学习技术。
“技术发展的趋势是机器生产机器。工业革命前夕,人们依赖手工作坊劳动,人是主要动力。工业革命 30 年后,蒸汽机作为动力。而再看看今天的车企里,组装都是由机械臂完成。AI 也是一种工业,它也会走同样的路径。”

演讲的最后,张家兴展示了封神榜大模型 AI 生成的一张画作《机器和人类一起探索宇宙星辰》。

“正如我今天的演讲主题‘预训练大模型时代的 AI 新范式’,预训练大模型带领整个 AI 领域走进了新的阶段,它对我们研究路径和思想理念的影响是巨大的,很幸运我们身在其中。”
9 月 1 至 3 日,2022 世界人工智能大会(简称 WAIC)在上海举办。在阿里巴巴达摩院主办的“大规模预训练模型”主题论坛上,IDEA 研究院认知计算与自然语言研究中心讲席科学家张家兴受邀发表了“预训练大模型时代的 AI 新范式”主题演讲。
论坛上,张家兴与阿里巴巴达摩院副院长周靖人、澜舟科技创始人周明、清华大学教授唐杰、深势科技创始人张林峰等在学术界、产业界中深耕大模型领域的思想引领者们,共同围绕“大规模预训练模型的创新、落地和开源开放”进行深入讨论,展示了国产大模型多元生态下的技术成果和思考。
过去两年,预训练模型的参数规模以前所未有的速度膨胀,在海量的无监督学习已能实现“感知智能”的今天,学者们更多地在思考如何推动 AI 表现出更加类人的推理和思考能力,让大模型带领人工智能走向“认知智能”时代。
大模型时代将给认知智能带来什么样的技术新范式?张家兴从“先验”、“闭环”、“大模型开源”和“AI 生产 AI”四个角度分享了他的思考,并展示他与团队的最新研究成果。
经过了数百万年的进化,每个呱呱坠地的人类婴儿都自带一个“出厂格式”,即只需要很少次数的样本示例就可以学会某个技能,甚至在没有样本的情况下也能无师自通,这就是先验。
预训练大模型让 AI 拥有了先验,并能越来越高效地学习,完成各种指定任务。张家兴思考,除了提升模型先验能力,让 AI 完成各种下游任务,是否还能在先验与下游任务之间,找到一种能让 AI 任务经验能更好地被反馈、迭代,并实现更高效积累、增长的方案?
他提出,在预训练大模型与下游任务间存在着一种“任务的表现型”。以分类任务举例,BERT 可以通过 classification 的方式选择 Label,T5 可以 seq2seq 的方式生成 Label,GPT 也可以直接通过 LM 的方式生成 Label。实际上预训练中的很多工作,就是在预训练大模型上选择或创造一种“表现型”,让大模型与各种下游任务彼此相适应。
UnifiedMC 就是张家兴携团队(IDEA 研究院认知计算与自然语言中心,简称 IDEA 研究院 CCNL),针对自然语言理解任务提出的一种新的表现型。
双向注意力模型通常在同等算力情况下能达到比生成模型更好的性能,以双向注意力模型为基础的 UnifiedMC,进一步通过将标签作为多选项作输入,提升了模型性能,以 2 亿的参数规模,就可达到谷歌的 5400 亿 PaLM 模型性能。
除了如何让大模型更好地适应文本分类等下游任务,他还在关注大模型在文本生成类任务上,能否通过推理能力的多步叠加,实现推理经验的增长,从而推动「AI 推理」无限接近「人的思考」。张家兴现场演示了 AI 根据「机器人统治世界」的输入,所展开的推理过程。经过一连串推理,AI 得出的结论是「人类要使用高能量武器消灭机器人」。
张家兴认为,“也许人类的思考,本质上就是无限的因果推理。而无限的多步推理,是机器的自主思考。”
在自然语言处理领域,许多人正在尝试构造训练的闭环,比如用生成模型生成数据,构建判别模型,再把判断返还给生成模型,让模型自己跟自己学,不再依赖人的数据输入。张家兴也在从事这一问题的研究,论坛上,他引用哲学家维特根斯坦的“语言游戏”说——人对语言的理解无非都来自于语言游戏,人和人之间形成一个闭环,最终理解了语言的意义。
“我们认为每个闭环的设计,都是一个语言游戏的设计(合作行为语言游戏)。所以提出了合作闭环模式。”张家兴表示,生成模型与判别模型间的合作,可能比对抗更能帮助研究者们构造出有效的闭环。
“我们设计了多种闭环,这套闭环设计,可以在 SOTA 模型的基础上再实现 1~2 个点的效果提升,”他在现场展示了一组性能数据,“过去很多人试过,效果都不太好。但为什么现在闭环成为了可能?因为预训练大模型给了 AI 更好的文本生成能力,给了闭环更好的「初始化」。”
预训练大模型作为认知智能的基石,被称为人工智能的大脑。预训练大模型的开源,对人工智能技术的整体演进意义非凡。
“下面我要展示的这两个榜单,正如刚刚周明教授所说,在座的各位嘉宾都是榜上常客了。”张家兴现场展示了 FewCLUE(小样本学习)和 ZeroCLUE(零样本学习)的榜单实况,封神榜开源大模型体系下的“二郎神”在两个榜单上同时登顶,澜舟的“孟子”、智源的“天枢”等选手紧随其后。
IDEA 研究院 CCNL 团队于 2021 年 11 月推出了封神榜系列开源大模型,随后又推出了封神框架。封神榜全方面开源一系列预训练大模型,目前已覆盖文本理解、文本摘要、文本生成、多模态生成等相关任务,致力于为工业界和学术界提供简单高效的解决方案。封神框架则提供丰富、真实的源代码和示例,用以模型训练及应用。
目前,封神榜系列开源大模型中的二郎神系列已获得数个中文榜单 SOTA 成绩。未来,封神榜还将持续更新。张家兴表示,希望更多公司、高校、机构能加入到这一开源行动,共建中文认知智能的基础设施。
大模型落地也是学工界共同关注的重要议题。
今天,那些应用在具体场景里的 AI 技术,为千行百业的数字化进程打下了良好的基础,但原有 AI 生产模式的不足也在落地过程中逐渐暴露。专用 AI 模型,往往由算法工程师“手工”编写。培养一个经验丰富的算法工程师周期长、难度大,生产过程对数据的要求也很高。成本高企,效益不明,这两个风险阻碍许多企业投身 AI 浪潮。
“用 AI 生产 AI 模型,可以解决现在 AI 模型落地成本过高、数据稀缺的问题。”张家兴介绍,GTSfactory AI 模型生产平台由 CCNL 团队自主开发,以具有高通用性和泛化能力的封神榜系列预训练大模型为底座,结合团队的 AI 系统工程能力,自动化生产出一个个小模型。
GTSfactory 有一套核心的复杂生产体系,Generator、Teacher、Student 是三种不同规模的预训练模型。Generator 利用预训练大模型强大的文本生成能力,为训练任务生成更多的训练样本。Teacher 利用预训练大模型天然的少样本学习能力,指导整个训练过程。Student 是用户可下载的轻量模型,综合了包括元学习、增量学习、半监督学习、预训练、自训练等各种机器学习技术。
“技术发展的趋势是机器生产机器。工业革命前夕,人们依赖手工作坊劳动,人是主要动力。工业革命 30 年后,蒸汽机作为动力。而再看看今天的车企里,组装都是由机械臂完成。AI 也是一种工业,它也会走同样的路径。”
演讲的最后,张家兴展示了封神榜大模型 AI 生成的一张画作《机器和人类一起探索宇宙星辰》。
“正如我今天的演讲主题‘预训练大模型时代的 AI 新范式’,预训练大模型带领整个 AI 领域走进了新的阶段,它对我们研究路径和思想理念的影响是巨大的,很幸运我们身在其中。”





粤ICP备2020119212号 © 2023年 粤港澳大湾区数字经济研究院(福田)版权所有  粤公网安备 44030402006206号
粤公网安备 44030402006206号

